mirror of
https://github.com/XRPLF/clio.git
synced 2025-11-16 17:55:50 +00:00
Compare commits
24 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
dfe18ed682 | ||
|
|
92a072d7a8 | ||
|
|
24fca61b56 | ||
|
|
ae8303fdc8 | ||
|
|
709a8463b8 | ||
|
|
84d31986d1 | ||
|
|
d50f229631 | ||
|
|
379c89fb02 | ||
|
|
81f7171368 | ||
|
|
629b35d1dd | ||
|
|
6fc4cee195 | ||
|
|
b01813ac3d | ||
|
|
6bf8c5bc4e | ||
|
|
2ffd98f895 | ||
|
|
3edead32ba | ||
|
|
28980734ae | ||
|
|
ce60c8f64d | ||
|
|
39ef2ae33c | ||
|
|
d83975e750 | ||
|
|
4468302852 | ||
|
|
a704cf7cfe | ||
|
|
05d09cc352 | ||
|
|
ae96ac7baf | ||
|
|
4579fa2f26 |
61
.github/workflows/build.yml
vendored
61
.github/workflows/build.yml
vendored
@@ -1,9 +1,9 @@
|
||||
name: Build Clio
|
||||
on:
|
||||
push:
|
||||
branches: [master, develop, develop-next]
|
||||
branches: [master, release, develop, develop-next]
|
||||
pull_request:
|
||||
branches: [master, develop, develop-next]
|
||||
branches: [master, release, develop, develop-next]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
@@ -18,9 +18,8 @@ jobs:
|
||||
uses: XRPLF/clio-gha/lint@main
|
||||
|
||||
build_clio:
|
||||
name: Build
|
||||
name: Build Clio
|
||||
runs-on: [self-hosted, Linux]
|
||||
needs: lint
|
||||
steps:
|
||||
|
||||
- name: Clone Clio repo
|
||||
@@ -34,26 +33,62 @@ jobs:
|
||||
path: clio_ci
|
||||
repository: 'XRPLF/clio-ci'
|
||||
|
||||
- name: Clone GitHub actions repo
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
repository: XRPLF/clio-gha
|
||||
path: gha # must be the same as defined in XRPLF/clio-gha
|
||||
|
||||
- name: Build
|
||||
uses: XRPLF/clio-gha/build@main
|
||||
|
||||
- name: Artifact packages
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: clio_packages
|
||||
path: ${{ github.workspace }}/*.deb
|
||||
|
||||
- name: Artifact clio_tests
|
||||
uses: actions/upload-artifact@v2
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: clio_tests
|
||||
path: clio_tests
|
||||
|
||||
sign:
|
||||
name: Sign packages
|
||||
needs: build_clio
|
||||
runs-on: ubuntu-20.04
|
||||
if: github.ref == 'refs/heads/master' || github.ref == 'refs/heads/release' || github.ref == 'refs/heads/develop'
|
||||
env:
|
||||
GPG_KEY_B64: ${{ secrets.GPG_KEY_B64 }}
|
||||
GPG_KEY_PASS_B64: ${{ secrets.GPG_KEY_PASS_B64 }}
|
||||
|
||||
steps:
|
||||
- name: Get package artifact
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
name: clio_packages
|
||||
|
||||
- name: find packages
|
||||
run: find . -name "*.deb"
|
||||
|
||||
- name: Install dpkg-sig
|
||||
run: |
|
||||
sudo apt-get update && sudo apt-get install -y dpkg-sig
|
||||
|
||||
- name: Sign Debian packages
|
||||
uses: XRPLF/clio-gha/sign@main
|
||||
|
||||
- name: Verify the signature
|
||||
run: |
|
||||
set -e
|
||||
for PKG in $(ls *.deb); do
|
||||
gpg --verify "${PKG}"
|
||||
done
|
||||
|
||||
- name: Get short SHA
|
||||
id: shortsha
|
||||
run: echo "::set-output name=sha8::$(echo ${GITHUB_SHA} | cut -c1-8)"
|
||||
|
||||
- name: Artifact Debian package
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: deb_package-${{ github.sha }}
|
||||
path: clio_ci/build/*.deb
|
||||
name: clio-deb-packages-${{ steps.shortsha.outputs.sha8 }}
|
||||
path: ${{ github.workspace }}/*.deb
|
||||
|
||||
test_clio:
|
||||
name: Test Clio
|
||||
|
||||
24
CMake/deps/Remove-bitset-operator.patch
Normal file
24
CMake/deps/Remove-bitset-operator.patch
Normal file
@@ -0,0 +1,24 @@
|
||||
From 5cd9d09d960fa489a0c4379880cd7615b1c16e55 Mon Sep 17 00:00:00 2001
|
||||
From: CJ Cobb <ccobb@ripple.com>
|
||||
Date: Wed, 10 Aug 2022 12:30:01 -0400
|
||||
Subject: [PATCH] Remove bitset operator !=
|
||||
|
||||
---
|
||||
src/ripple/protocol/Feature.h | 1 -
|
||||
1 file changed, 1 deletion(-)
|
||||
|
||||
diff --git a/src/ripple/protocol/Feature.h b/src/ripple/protocol/Feature.h
|
||||
index b3ecb099b..6424be411 100644
|
||||
--- a/src/ripple/protocol/Feature.h
|
||||
+++ b/src/ripple/protocol/Feature.h
|
||||
@@ -126,7 +126,6 @@ class FeatureBitset : private std::bitset<detail::numFeatures>
|
||||
public:
|
||||
using base::bitset;
|
||||
using base::operator==;
|
||||
- using base::operator!=;
|
||||
|
||||
using base::all;
|
||||
using base::any;
|
||||
--
|
||||
2.32.0
|
||||
|
||||
@@ -1,11 +1,13 @@
|
||||
set(RIPPLED_REPO "https://github.com/ripple/rippled.git")
|
||||
set(RIPPLED_BRANCH "1.9.0")
|
||||
set(RIPPLED_BRANCH "1.9.2")
|
||||
set(NIH_CACHE_ROOT "${CMAKE_CURRENT_BINARY_DIR}" CACHE INTERNAL "")
|
||||
set(patch_command ! grep operator!= src/ripple/protocol/Feature.h || git apply < ${CMAKE_CURRENT_SOURCE_DIR}/CMake/deps/Remove-bitset-operator.patch)
|
||||
message(STATUS "Cloning ${RIPPLED_REPO} branch ${RIPPLED_BRANCH}")
|
||||
FetchContent_Declare(rippled
|
||||
GIT_REPOSITORY "${RIPPLED_REPO}"
|
||||
GIT_TAG "${RIPPLED_BRANCH}"
|
||||
GIT_SHALLOW ON
|
||||
PATCH_COMMAND "${patch_command}"
|
||||
)
|
||||
|
||||
FetchContent_GetProperties(rippled)
|
||||
|
||||
@@ -2,6 +2,10 @@ cmake_minimum_required(VERSION 3.16.3)
|
||||
|
||||
project(clio)
|
||||
|
||||
if(CMAKE_CXX_COMPILER_VERSION VERSION_LESS 11)
|
||||
message(FATAL_ERROR "GCC 11+ required for building clio")
|
||||
endif()
|
||||
|
||||
option(BUILD_TESTS "Build tests" TRUE)
|
||||
|
||||
option(VERBOSE "Verbose build" TRUE)
|
||||
@@ -12,7 +16,7 @@ endif()
|
||||
|
||||
if(NOT GIT_COMMIT_HASH)
|
||||
if(VERBOSE)
|
||||
message(WARNING "GIT_COMMIT_HASH not provided...looking for git")
|
||||
message("GIT_COMMIT_HASH not provided...looking for git")
|
||||
endif()
|
||||
find_package(Git)
|
||||
if(Git_FOUND)
|
||||
@@ -45,12 +49,12 @@ target_sources(clio PRIVATE
|
||||
## Backend
|
||||
src/backend/BackendInterface.cpp
|
||||
src/backend/CassandraBackend.cpp
|
||||
src/backend/LayeredCache.cpp
|
||||
src/backend/Pg.cpp
|
||||
src/backend/PostgresBackend.cpp
|
||||
src/backend/SimpleCache.cpp
|
||||
## ETL
|
||||
src/etl/ETLSource.cpp
|
||||
src/etl/NFTHelpers.cpp
|
||||
src/etl/ReportingETL.cpp
|
||||
## Subscriptions
|
||||
src/subscriptions/SubscriptionManager.cpp
|
||||
@@ -69,6 +73,8 @@ target_sources(clio PRIVATE
|
||||
src/rpc/handlers/AccountObjects.cpp
|
||||
src/rpc/handlers/GatewayBalances.cpp
|
||||
src/rpc/handlers/NoRippleCheck.cpp
|
||||
# NFT
|
||||
src/rpc/handlers/NFTInfo.cpp
|
||||
# Ledger
|
||||
src/rpc/handlers/Ledger.cpp
|
||||
src/rpc/handlers/LedgerData.cpp
|
||||
|
||||
37
README.md
37
README.md
@@ -1,9 +1,3 @@
|
||||
[](https://github.com/legleux/clio/actions/workflows/build.yml)
|
||||
|
||||
|
||||
**Status:** This software is in beta mode. We encourage anyone to try it out and
|
||||
report any issues they discover. Version 1.0 coming soon.
|
||||
|
||||
# Clio
|
||||
Clio is an XRP Ledger API server. Clio is optimized for RPC calls, over WebSocket or JSON-RPC. Validated
|
||||
historical ledger and transaction data are stored in a more space-efficient format,
|
||||
@@ -28,7 +22,7 @@ from which data can be extracted. The rippled node does not need to be running o
|
||||
|
||||
## Building
|
||||
|
||||
Clio is built with CMake. Clio requires c++20, and boost 1.75.0 or later.
|
||||
Clio is built with CMake. Clio requires at least GCC-11 (C++20), and Boost 1.75.0 or later.
|
||||
|
||||
Use these instructions to build a Clio executable from the source. These instructions were tested on Ubuntu 20.04 LTS.
|
||||
|
||||
@@ -146,25 +140,38 @@ which can cause high latencies. A possible alternative to this is to just deploy
|
||||
a database in each region, and the Clio nodes in each region use their region's database.
|
||||
This is effectively two systems.
|
||||
|
||||
## Developing against `rippled` in standalone mode
|
||||
|
||||
If you wish you develop against a `rippled` instance running in standalone
|
||||
mode there are a few quirks of both clio and rippled you need to keep in mind.
|
||||
You must:
|
||||
|
||||
1. Advance the `rippled` ledger to at least ledger 256
|
||||
2. Wait 10 minutes before first starting clio against this standalone node.
|
||||
|
||||
## Logging
|
||||
Clio provides several logging options, all are configurable via the config file and are detailed below.
|
||||
|
||||
`log_level`: The minimum level of severity at which the log message will be outputted.
|
||||
Severity options are `trace`, `debug`, `info`, `warning`, `error`, `fatal`.
|
||||
`log_level`: The minimum level of severity at which the log message will be outputted.
|
||||
Severity options are `trace`, `debug`, `info`, `warning`, `error`, `fatal`.
|
||||
|
||||
`log_to_console`: Enable/disable log output to console. Options are `true`/`false`.
|
||||
`log_to_console`: Enable/disable log output to console. Options are `true`/`false`. Defaults to true.
|
||||
|
||||
`log_to_file`: Enable/disable log saving to files in persistent local storage. Options are `true`/`false`.
|
||||
|
||||
`log_directory`: Path to the directory where log files are stored. If such directory doesn't exist, Clio will create it.
|
||||
`log_directory`: Path to the directory where log files are stored. If such directory doesn't exist, Clio will create it. If not specified, logs are not written to a file.
|
||||
|
||||
`log_rotation_size`: The max size of the log file in **megabytes** before it will rotate into a smaller file.
|
||||
|
||||
`log_directory_max_size`: The max size of the log directory in **megabytes** before old log files will be
|
||||
`log_directory_max_size`: The max size of the log directory in **megabytes** before old log files will be
|
||||
deleted to free up space.
|
||||
|
||||
`log_rotation_hour_interval`: The time interval in **hours** after the last log rotation to automatically
|
||||
rotate the current log file.
|
||||
|
||||
Note, time-based log rotation occurs dependently on size-based log rotation, where if a
|
||||
size-based log rotation occurs, the timer for the time-based rotation will reset.
|
||||
size-based log rotation occurs, the timer for the time-based rotation will reset.
|
||||
|
||||
## Cassandra / Scylla Administration
|
||||
|
||||
Since Clio relies on either Cassandra or Scylla for its database backend, here are some important considerations:
|
||||
|
||||
- Scylla, by default, will reserve all free RAM on a machine for itself. If you are running `rippled` or other services on the same machine, restrict its memory usage using the `--memory` argument: https://docs.scylladb.com/getting-started/scylla-in-a-shared-environment/
|
||||
|
||||
@@ -276,7 +276,8 @@ BackendInterface::fetchLedgerPage(
|
||||
else if (!outOfOrder)
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(error)
|
||||
<< __func__ << " incorrect successor table. key = "
|
||||
<< __func__
|
||||
<< " deleted or non-existent object in successor table. key = "
|
||||
<< ripple::strHex(keys[i]) << " - seq = " << ledgerSequence;
|
||||
std::stringstream msg;
|
||||
for (size_t j = 0; j < objects.size(); ++j)
|
||||
@@ -284,7 +285,6 @@ BackendInterface::fetchLedgerPage(
|
||||
msg << " - " << ripple::strHex(keys[j]);
|
||||
}
|
||||
BOOST_LOG_TRIVIAL(error) << __func__ << msg.str();
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
if (keys.size() && !reachedEnd)
|
||||
|
||||
@@ -162,12 +162,12 @@ public:
|
||||
std::vector<ripple::uint256> const& hashes,
|
||||
boost::asio::yield_context& yield) const = 0;
|
||||
|
||||
virtual AccountTransactions
|
||||
virtual TransactionsAndCursor
|
||||
fetchAccountTransactions(
|
||||
ripple::AccountID const& account,
|
||||
std::uint32_t const limit,
|
||||
bool forward,
|
||||
std::optional<AccountTransactionsCursor> const& cursor,
|
||||
std::optional<TransactionsCursor> const& cursor,
|
||||
boost::asio::yield_context& yield) const = 0;
|
||||
|
||||
virtual std::vector<TransactionAndMetadata>
|
||||
@@ -180,6 +180,21 @@ public:
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const = 0;
|
||||
|
||||
// *** NFT methods
|
||||
virtual std::optional<NFT>
|
||||
fetchNFT(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const = 0;
|
||||
|
||||
virtual TransactionsAndCursor
|
||||
fetchNFTTransactions(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const limit,
|
||||
bool const forward,
|
||||
std::optional<TransactionsCursor> const& cursorIn,
|
||||
boost::asio::yield_context& yield) const = 0;
|
||||
|
||||
// *** state data methods
|
||||
std::optional<Blob>
|
||||
fetchLedgerObject(
|
||||
@@ -285,9 +300,15 @@ public:
|
||||
std::string&& transaction,
|
||||
std::string&& metadata) = 0;
|
||||
|
||||
virtual void
|
||||
writeNFTs(std::vector<NFTsData>&& data) = 0;
|
||||
|
||||
virtual void
|
||||
writeAccountTransactions(std::vector<AccountTransactionsData>&& data) = 0;
|
||||
|
||||
virtual void
|
||||
writeNFTTransactions(std::vector<NFTTransactionsData>&& data) = 0;
|
||||
|
||||
virtual void
|
||||
writeSuccessor(
|
||||
std::string&& key,
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
#include <ripple/app/tx/impl/details/NFTokenUtils.h>
|
||||
#include <backend/CassandraBackend.h>
|
||||
#include <backend/DBHelpers.h>
|
||||
#include <functional>
|
||||
#include <unordered_map>
|
||||
|
||||
namespace Backend {
|
||||
|
||||
// Type alias for async completion handlers
|
||||
@@ -256,6 +258,7 @@ CassandraBackend::writeLedger(
|
||||
"ledger_hash");
|
||||
ledgerSequence_ = ledgerInfo.seq;
|
||||
}
|
||||
|
||||
void
|
||||
CassandraBackend::writeAccountTransactions(
|
||||
std::vector<AccountTransactionsData>&& data)
|
||||
@@ -266,11 +269,11 @@ CassandraBackend::writeAccountTransactions(
|
||||
{
|
||||
makeAndExecuteAsyncWrite(
|
||||
this,
|
||||
std::move(std::make_tuple(
|
||||
std::make_tuple(
|
||||
std::move(account),
|
||||
record.ledgerSequence,
|
||||
record.transactionIndex,
|
||||
record.txHash)),
|
||||
record.txHash),
|
||||
[this](auto& params) {
|
||||
CassandraStatement statement(insertAccountTx_);
|
||||
auto& [account, lgrSeq, txnIdx, hash] = params.data;
|
||||
@@ -283,6 +286,31 @@ CassandraBackend::writeAccountTransactions(
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void
|
||||
CassandraBackend::writeNFTTransactions(std::vector<NFTTransactionsData>&& data)
|
||||
{
|
||||
for (NFTTransactionsData const& record : data)
|
||||
{
|
||||
makeAndExecuteAsyncWrite(
|
||||
this,
|
||||
std::make_tuple(
|
||||
record.tokenID,
|
||||
record.ledgerSequence,
|
||||
record.transactionIndex,
|
||||
record.txHash),
|
||||
[this](auto const& params) {
|
||||
CassandraStatement statement(insertNFTTx_);
|
||||
auto const& [tokenID, lgrSeq, txnIdx, txHash] = params.data;
|
||||
statement.bindNextBytes(tokenID);
|
||||
statement.bindNextIntTuple(lgrSeq, txnIdx);
|
||||
statement.bindNextBytes(txHash);
|
||||
return statement;
|
||||
},
|
||||
"nf_token_transactions");
|
||||
}
|
||||
}
|
||||
|
||||
void
|
||||
CassandraBackend::writeTransaction(
|
||||
std::string&& hash,
|
||||
@@ -325,6 +353,43 @@ CassandraBackend::writeTransaction(
|
||||
"transaction");
|
||||
}
|
||||
|
||||
void
|
||||
CassandraBackend::writeNFTs(std::vector<NFTsData>&& data)
|
||||
{
|
||||
for (NFTsData const& record : data)
|
||||
{
|
||||
makeAndExecuteAsyncWrite(
|
||||
this,
|
||||
std::make_tuple(
|
||||
record.tokenID,
|
||||
record.ledgerSequence,
|
||||
record.owner,
|
||||
record.isBurned),
|
||||
[this](auto const& params) {
|
||||
CassandraStatement statement{insertNFT_};
|
||||
auto const& [tokenID, lgrSeq, owner, isBurned] = params.data;
|
||||
statement.bindNextBytes(tokenID);
|
||||
statement.bindNextInt(lgrSeq);
|
||||
statement.bindNextBytes(owner);
|
||||
statement.bindNextBoolean(isBurned);
|
||||
return statement;
|
||||
},
|
||||
"nf_tokens");
|
||||
|
||||
makeAndExecuteAsyncWrite(
|
||||
this,
|
||||
std::make_tuple(record.tokenID),
|
||||
[this](auto const& params) {
|
||||
CassandraStatement statement{insertIssuerNFT_};
|
||||
auto const& [tokenID] = params.data;
|
||||
statement.bindNextBytes(ripple::nft::getIssuer(tokenID));
|
||||
statement.bindNextBytes(tokenID);
|
||||
return statement;
|
||||
},
|
||||
"issuer_nf_tokens");
|
||||
}
|
||||
}
|
||||
|
||||
std::optional<LedgerRange>
|
||||
CassandraBackend::hardFetchLedgerRange(boost::asio::yield_context& yield) const
|
||||
{
|
||||
@@ -502,12 +567,113 @@ CassandraBackend::fetchAllTransactionHashesInLedger(
|
||||
return hashes;
|
||||
}
|
||||
|
||||
AccountTransactions
|
||||
std::optional<NFT>
|
||||
CassandraBackend::fetchNFT(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
CassandraStatement statement{selectNFT_};
|
||||
statement.bindNextBytes(tokenID);
|
||||
statement.bindNextInt(ledgerSequence);
|
||||
CassandraResult response = executeAsyncRead(statement, yield);
|
||||
if (!response)
|
||||
return {};
|
||||
|
||||
NFT result;
|
||||
result.tokenID = tokenID;
|
||||
result.ledgerSequence = response.getUInt32();
|
||||
result.owner = response.getBytes();
|
||||
result.isBurned = response.getBool();
|
||||
return result;
|
||||
}
|
||||
|
||||
TransactionsAndCursor
|
||||
CassandraBackend::fetchNFTTransactions(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const limit,
|
||||
bool const forward,
|
||||
std::optional<TransactionsCursor> const& cursorIn,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
auto cursor = cursorIn;
|
||||
auto rng = fetchLedgerRange();
|
||||
if (!rng)
|
||||
return {{}, {}};
|
||||
|
||||
CassandraStatement statement = forward
|
||||
? CassandraStatement(selectNFTTxForward_)
|
||||
: CassandraStatement(selectNFTTx_);
|
||||
|
||||
statement.bindNextBytes(tokenID);
|
||||
|
||||
if (cursor)
|
||||
{
|
||||
statement.bindNextIntTuple(
|
||||
cursor->ledgerSequence, cursor->transactionIndex);
|
||||
BOOST_LOG_TRIVIAL(debug) << " token_id = " << ripple::strHex(tokenID)
|
||||
<< " tuple = " << cursor->ledgerSequence
|
||||
<< " : " << cursor->transactionIndex;
|
||||
}
|
||||
else
|
||||
{
|
||||
int const seq = forward ? rng->minSequence : rng->maxSequence;
|
||||
int const placeHolder =
|
||||
forward ? 0 : std::numeric_limits<std::uint32_t>::max();
|
||||
|
||||
statement.bindNextIntTuple(placeHolder, placeHolder);
|
||||
BOOST_LOG_TRIVIAL(debug)
|
||||
<< " token_id = " << ripple::strHex(tokenID) << " idx = " << seq
|
||||
<< " tuple = " << placeHolder;
|
||||
}
|
||||
|
||||
statement.bindNextUInt(limit);
|
||||
|
||||
CassandraResult result = executeAsyncRead(statement, yield);
|
||||
|
||||
if (!result.hasResult())
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " - no rows returned";
|
||||
return {};
|
||||
}
|
||||
|
||||
std::vector<ripple::uint256> hashes = {};
|
||||
auto numRows = result.numRows();
|
||||
BOOST_LOG_TRIVIAL(info) << "num_rows = " << numRows;
|
||||
do
|
||||
{
|
||||
hashes.push_back(result.getUInt256());
|
||||
if (--numRows == 0)
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " setting cursor";
|
||||
auto const [lgrSeq, txnIdx] = result.getInt64Tuple();
|
||||
cursor = {
|
||||
static_cast<std::uint32_t>(lgrSeq),
|
||||
static_cast<std::uint32_t>(txnIdx)};
|
||||
|
||||
if (forward)
|
||||
++cursor->transactionIndex;
|
||||
}
|
||||
} while (result.nextRow());
|
||||
|
||||
auto txns = fetchTransactions(hashes, yield);
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " txns = " << txns.size();
|
||||
|
||||
if (txns.size() == limit)
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " returning cursor";
|
||||
return {txns, cursor};
|
||||
}
|
||||
|
||||
return {txns, {}};
|
||||
}
|
||||
|
||||
TransactionsAndCursor
|
||||
CassandraBackend::fetchAccountTransactions(
|
||||
ripple::AccountID const& account,
|
||||
std::uint32_t const limit,
|
||||
bool const forward,
|
||||
std::optional<AccountTransactionsCursor> const& cursorIn,
|
||||
std::optional<TransactionsCursor> const& cursorIn,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
auto rng = fetchLedgerRange();
|
||||
@@ -535,8 +701,8 @@ CassandraBackend::fetchAccountTransactions(
|
||||
}
|
||||
else
|
||||
{
|
||||
int seq = forward ? rng->minSequence : rng->maxSequence;
|
||||
int placeHolder =
|
||||
int const seq = forward ? rng->minSequence : rng->maxSequence;
|
||||
int const placeHolder =
|
||||
forward ? 0 : std::numeric_limits<std::uint32_t>::max();
|
||||
|
||||
statement.bindNextIntTuple(placeHolder, placeHolder);
|
||||
@@ -584,6 +750,7 @@ CassandraBackend::fetchAccountTransactions(
|
||||
|
||||
return {txns, {}};
|
||||
}
|
||||
|
||||
std::optional<ripple::uint256>
|
||||
CassandraBackend::doFetchSuccessorKey(
|
||||
ripple::uint256 key,
|
||||
@@ -1179,6 +1346,64 @@ CassandraBackend::open(bool readOnly)
|
||||
<< " LIMIT 1";
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "CREATE TABLE IF NOT EXISTS " << tablePrefix << "nf_tokens"
|
||||
<< " ("
|
||||
<< " token_id blob,"
|
||||
<< " sequence bigint,"
|
||||
<< " owner blob,"
|
||||
<< " is_burned boolean,"
|
||||
<< " PRIMARY KEY (token_id, sequence)"
|
||||
<< " )"
|
||||
<< " WITH CLUSTERING ORDER BY (sequence DESC)"
|
||||
<< " AND default_time_to_live = " << ttl;
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT * FROM " << tablePrefix << "nf_tokens"
|
||||
<< " LIMIT 1";
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "CREATE TABLE IF NOT EXISTS " << tablePrefix
|
||||
<< "issuer_nf_tokens"
|
||||
<< " ("
|
||||
<< " issuer blob,"
|
||||
<< " token_id blob,"
|
||||
<< " PRIMARY KEY (issuer, token_id)"
|
||||
<< " )";
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT * FROM " << tablePrefix << "issuer_nf_tokens"
|
||||
<< " LIMIT 1";
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "CREATE TABLE IF NOT EXISTS " << tablePrefix
|
||||
<< "nf_token_transactions"
|
||||
<< " ("
|
||||
<< " token_id blob,"
|
||||
<< " seq_idx tuple<bigint, bigint>,"
|
||||
<< " hash blob,"
|
||||
<< " PRIMARY KEY (token_id, seq_idx)"
|
||||
<< " )"
|
||||
<< " WITH CLUSTERING ORDER BY (seq_idx DESC)"
|
||||
<< " AND default_time_to_live = " << ttl;
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT * FROM " << tablePrefix << "nf_token_transactions"
|
||||
<< " LIMIT 1";
|
||||
if (!executeSimpleStatement(query.str()))
|
||||
continue;
|
||||
|
||||
setupSessionAndTable = true;
|
||||
}
|
||||
|
||||
@@ -1296,6 +1521,57 @@ CassandraBackend::open(bool readOnly)
|
||||
if (!selectAccountTxForward_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "INSERT INTO " << tablePrefix << "nf_tokens"
|
||||
<< " (token_id,sequence,owner,is_burned)"
|
||||
<< " VALUES (?,?,?,?)";
|
||||
if (!insertNFT_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT sequence,owner,is_burned"
|
||||
<< " FROM " << tablePrefix << "nf_tokens WHERE"
|
||||
<< " token_id = ? AND"
|
||||
<< " sequence <= ?"
|
||||
<< " ORDER BY sequence DESC"
|
||||
<< " LIMIT 1";
|
||||
if (!selectNFT_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "INSERT INTO " << tablePrefix << "issuer_nf_tokens"
|
||||
<< " (issuer,token_id)"
|
||||
<< " VALUES (?,?)";
|
||||
if (!insertIssuerNFT_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "INSERT INTO " << tablePrefix << "nf_token_transactions"
|
||||
<< " (token_id,seq_idx,hash)"
|
||||
<< " VALUES (?,?,?)";
|
||||
if (!insertNFTTx_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT hash,seq_idx"
|
||||
<< " FROM " << tablePrefix << "nf_token_transactions WHERE"
|
||||
<< " token_id = ? AND"
|
||||
<< " seq_idx < ?"
|
||||
<< " ORDER BY seq_idx DESC"
|
||||
<< " LIMIT ?";
|
||||
if (!selectNFTTx_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << "SELECT hash,seq_idx"
|
||||
<< " FROM " << tablePrefix << "nf_token_transactions WHERE"
|
||||
<< " token_id = ? AND"
|
||||
<< " seq_idx >= ?"
|
||||
<< " ORDER BY seq_idx ASC"
|
||||
<< " LIMIT ?";
|
||||
if (!selectNFTTxForward_.prepareStatement(query, session_.get()))
|
||||
continue;
|
||||
|
||||
query.str("");
|
||||
query << " INSERT INTO " << tablePrefix << "ledgers "
|
||||
<< " (sequence, header) VALUES(?,?)";
|
||||
|
||||
@@ -115,7 +115,7 @@ public:
|
||||
throw std::runtime_error(
|
||||
"CassandraStatement::bindNextBoolean - statement_ is null");
|
||||
CassError rc = cass_statement_bind_bool(
|
||||
statement_, 1, static_cast<cass_bool_t>(val));
|
||||
statement_, curBindingIndex_, static_cast<cass_bool_t>(val));
|
||||
if (rc != CASS_OK)
|
||||
{
|
||||
std::stringstream ss;
|
||||
@@ -481,6 +481,33 @@ public:
|
||||
return {first, second};
|
||||
}
|
||||
|
||||
// TODO: should be replaced with a templated implementation as is very
|
||||
// similar to other getters
|
||||
bool
|
||||
getBool()
|
||||
{
|
||||
if (!row_)
|
||||
{
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - no result";
|
||||
BOOST_LOG_TRIVIAL(error) << msg.str();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
cass_bool_t val;
|
||||
CassError rc =
|
||||
cass_value_get_bool(cass_row_get_column(row_, curGetIndex_), &val);
|
||||
if (rc != CASS_OK)
|
||||
{
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - error getting value: " << rc << ", "
|
||||
<< cass_error_desc(rc);
|
||||
BOOST_LOG_TRIVIAL(error) << msg.str();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
++curGetIndex_;
|
||||
return val;
|
||||
}
|
||||
|
||||
~CassandraResult()
|
||||
{
|
||||
if (result_ != nullptr)
|
||||
@@ -599,6 +626,12 @@ private:
|
||||
CassandraPreparedStatement insertAccountTx_;
|
||||
CassandraPreparedStatement selectAccountTx_;
|
||||
CassandraPreparedStatement selectAccountTxForward_;
|
||||
CassandraPreparedStatement insertNFT_;
|
||||
CassandraPreparedStatement selectNFT_;
|
||||
CassandraPreparedStatement insertIssuerNFT_;
|
||||
CassandraPreparedStatement insertNFTTx_;
|
||||
CassandraPreparedStatement selectNFTTx_;
|
||||
CassandraPreparedStatement selectNFTTxForward_;
|
||||
CassandraPreparedStatement insertLedgerHeader_;
|
||||
CassandraPreparedStatement insertLedgerHash_;
|
||||
CassandraPreparedStatement updateLedgerRange_;
|
||||
@@ -683,12 +716,12 @@ public:
|
||||
open_ = false;
|
||||
}
|
||||
|
||||
AccountTransactions
|
||||
TransactionsAndCursor
|
||||
fetchAccountTransactions(
|
||||
ripple::AccountID const& account,
|
||||
std::uint32_t const limit,
|
||||
bool forward,
|
||||
std::optional<AccountTransactionsCursor> const& cursor,
|
||||
std::optional<TransactionsCursor> const& cursor,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
bool
|
||||
@@ -852,6 +885,20 @@ public:
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
std::optional<NFT>
|
||||
fetchNFT(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
TransactionsAndCursor
|
||||
fetchNFTTransactions(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const limit,
|
||||
bool const forward,
|
||||
std::optional<TransactionsCursor> const& cursorIn,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
// Synchronously fetch the object with key key, as of ledger with sequence
|
||||
// sequence
|
||||
std::optional<Blob>
|
||||
@@ -941,6 +988,9 @@ public:
|
||||
writeAccountTransactions(
|
||||
std::vector<AccountTransactionsData>&& data) override;
|
||||
|
||||
void
|
||||
writeNFTTransactions(std::vector<NFTTransactionsData>&& data) override;
|
||||
|
||||
void
|
||||
writeTransaction(
|
||||
std::string&& hash,
|
||||
@@ -949,6 +999,9 @@ public:
|
||||
std::string&& transaction,
|
||||
std::string&& metadata) override;
|
||||
|
||||
void
|
||||
writeNFTs(std::vector<NFTsData>&& data) override;
|
||||
|
||||
void
|
||||
startWrites() const override
|
||||
{
|
||||
|
||||
@@ -9,8 +9,8 @@
|
||||
#include <backend/Pg.h>
|
||||
#include <backend/Types.h>
|
||||
|
||||
/// Struct used to keep track of what to write to transactions and
|
||||
/// account_transactions tables in Postgres
|
||||
/// Struct used to keep track of what to write to
|
||||
/// account_transactions/account_tx tables
|
||||
struct AccountTransactionsData
|
||||
{
|
||||
boost::container::flat_set<ripple::AccountID> accounts;
|
||||
@@ -32,6 +32,57 @@ struct AccountTransactionsData
|
||||
AccountTransactionsData() = default;
|
||||
};
|
||||
|
||||
/// Represents a link from a tx to an NFT that was targeted/modified/created
|
||||
/// by it. Gets written to nf_token_transactions table and the like.
|
||||
struct NFTTransactionsData
|
||||
{
|
||||
ripple::uint256 tokenID;
|
||||
std::uint32_t ledgerSequence;
|
||||
std::uint32_t transactionIndex;
|
||||
ripple::uint256 txHash;
|
||||
|
||||
NFTTransactionsData(
|
||||
ripple::uint256 const& tokenID,
|
||||
ripple::TxMeta const& meta,
|
||||
ripple::uint256 const& txHash)
|
||||
: tokenID(tokenID)
|
||||
, ledgerSequence(meta.getLgrSeq())
|
||||
, transactionIndex(meta.getIndex())
|
||||
, txHash(txHash)
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
/// Represents an NFT state at a particular ledger. Gets written to nf_tokens
|
||||
/// table and the like.
|
||||
struct NFTsData
|
||||
{
|
||||
ripple::uint256 tokenID;
|
||||
std::uint32_t ledgerSequence;
|
||||
|
||||
// The transaction index is only stored because we want to store only the
|
||||
// final state of an NFT per ledger. Since we pull this from transactions
|
||||
// we keep track of which tx index created this so we can de-duplicate, as
|
||||
// it is possible for one ledger to have multiple txs that change the
|
||||
// state of the same NFT.
|
||||
std::uint32_t transactionIndex;
|
||||
ripple::AccountID owner;
|
||||
bool isBurned;
|
||||
|
||||
NFTsData(
|
||||
ripple::uint256 const& tokenID,
|
||||
ripple::AccountID const& owner,
|
||||
ripple::TxMeta const& meta,
|
||||
bool isBurned)
|
||||
: tokenID(tokenID)
|
||||
, ledgerSequence(meta.getLgrSeq())
|
||||
, transactionIndex(meta.getIndex())
|
||||
, owner(owner)
|
||||
, isBurned(isBurned)
|
||||
{
|
||||
}
|
||||
};
|
||||
|
||||
template <class T>
|
||||
inline bool
|
||||
isOffer(T const& object)
|
||||
|
||||
@@ -1,110 +0,0 @@
|
||||
#include <backend/LayeredCache.h>
|
||||
namespace Backend {
|
||||
|
||||
void
|
||||
LayeredCache::insert(
|
||||
ripple::uint256 const& key,
|
||||
Blob const& value,
|
||||
uint32_t seq)
|
||||
{
|
||||
auto entry = map_[key];
|
||||
// stale insert, do nothing
|
||||
if (seq <= entry.recent.seq)
|
||||
return;
|
||||
entry.old = entry.recent;
|
||||
entry.recent = {seq, value};
|
||||
if (value.empty())
|
||||
pendingDeletes_.push_back(key);
|
||||
if (!entry.old.blob.empty())
|
||||
pendingSweeps_.push_back(key);
|
||||
}
|
||||
|
||||
std::optional<Blob>
|
||||
LayeredCache::select(CacheEntry const& entry, uint32_t seq) const
|
||||
{
|
||||
if (seq < entry.old.seq)
|
||||
return {};
|
||||
if (seq < entry.recent.seq && !entry.old.blob.empty())
|
||||
return entry.old.blob;
|
||||
if (!entry.recent.blob.empty())
|
||||
return entry.recent.blob;
|
||||
return {};
|
||||
}
|
||||
void
|
||||
LayeredCache::update(std::vector<LedgerObject> const& blobs, uint32_t seq)
|
||||
{
|
||||
std::unique_lock lck{mtx_};
|
||||
if (seq > mostRecentSequence_)
|
||||
mostRecentSequence_ = seq;
|
||||
for (auto const& k : pendingSweeps_)
|
||||
{
|
||||
auto e = map_[k];
|
||||
e.old = {};
|
||||
}
|
||||
for (auto const& k : pendingDeletes_)
|
||||
{
|
||||
map_.erase(k);
|
||||
}
|
||||
for (auto const& b : blobs)
|
||||
{
|
||||
insert(b.key, b.blob, seq);
|
||||
}
|
||||
}
|
||||
std::optional<LedgerObject>
|
||||
LayeredCache::getSuccessor(ripple::uint256 const& key, uint32_t seq) const
|
||||
{
|
||||
ripple::uint256 curKey = key;
|
||||
while (true)
|
||||
{
|
||||
std::shared_lock lck{mtx_};
|
||||
if (seq < mostRecentSequence_ - 1)
|
||||
return {};
|
||||
auto e = map_.upper_bound(curKey);
|
||||
if (e == map_.end())
|
||||
return {};
|
||||
auto const& entry = e->second;
|
||||
auto blob = select(entry, seq);
|
||||
if (!blob)
|
||||
{
|
||||
curKey = e->first;
|
||||
continue;
|
||||
}
|
||||
else
|
||||
return {{e->first, *blob}};
|
||||
}
|
||||
}
|
||||
std::optional<LedgerObject>
|
||||
LayeredCache::getPredecessor(ripple::uint256 const& key, uint32_t seq) const
|
||||
{
|
||||
ripple::uint256 curKey = key;
|
||||
std::shared_lock lck{mtx_};
|
||||
while (true)
|
||||
{
|
||||
if (seq < mostRecentSequence_ - 1)
|
||||
return {};
|
||||
auto e = map_.lower_bound(curKey);
|
||||
--e;
|
||||
if (e == map_.begin())
|
||||
return {};
|
||||
auto const& entry = e->second;
|
||||
auto blob = select(entry, seq);
|
||||
if (!blob)
|
||||
{
|
||||
curKey = e->first;
|
||||
continue;
|
||||
}
|
||||
else
|
||||
return {{e->first, *blob}};
|
||||
}
|
||||
}
|
||||
std::optional<Blob>
|
||||
LayeredCache::get(ripple::uint256 const& key, uint32_t seq) const
|
||||
{
|
||||
std::shared_lock lck{mtx_};
|
||||
auto e = map_.find(key);
|
||||
if (e == map_.end())
|
||||
return {};
|
||||
auto const& entry = e->second;
|
||||
return select(entry, seq);
|
||||
}
|
||||
} // namespace Backend
|
||||
@@ -1,73 +0,0 @@
|
||||
#ifndef CLIO_LAYEREDCACHE_H_INCLUDED
|
||||
#define CLIO_LAYEREDCACHE_H_INCLUDED
|
||||
|
||||
#include <ripple/basics/base_uint.h>
|
||||
#include <backend/Types.h>
|
||||
#include <map>
|
||||
#include <mutex>
|
||||
#include <shared_mutex>
|
||||
#include <utility>
|
||||
#include <vector>
|
||||
namespace Backend {
|
||||
class LayeredCache
|
||||
{
|
||||
struct SeqBlobPair
|
||||
{
|
||||
uint32_t seq;
|
||||
Blob blob;
|
||||
};
|
||||
struct CacheEntry
|
||||
{
|
||||
SeqBlobPair recent;
|
||||
SeqBlobPair old;
|
||||
};
|
||||
|
||||
std::map<ripple::uint256, CacheEntry> map_;
|
||||
std::vector<ripple::uint256> pendingDeletes_;
|
||||
std::vector<ripple::uint256> pendingSweeps_;
|
||||
mutable std::shared_mutex mtx_;
|
||||
uint32_t mostRecentSequence_;
|
||||
|
||||
void
|
||||
insert(ripple::uint256 const& key, Blob const& value, uint32_t seq);
|
||||
|
||||
/*
|
||||
void
|
||||
insert(ripple::uint256 const& key, Blob const& value, uint32_t seq)
|
||||
{
|
||||
map_.emplace(key,{{seq,value,{}});
|
||||
}
|
||||
void
|
||||
update(ripple::uint256 const& key, Blob const& value, uint32_t seq)
|
||||
{
|
||||
auto& entry = map_.find(key);
|
||||
entry.old = entry.recent;
|
||||
entry.recent = {seq, value};
|
||||
pendingSweeps_.push_back(key);
|
||||
}
|
||||
void
|
||||
erase(ripple::uint256 const& key, uint32_t seq)
|
||||
{
|
||||
update(key, {}, seq);
|
||||
pendingDeletes_.push_back(key);
|
||||
}
|
||||
*/
|
||||
std::optional<Blob>
|
||||
select(CacheEntry const& entry, uint32_t seq) const;
|
||||
|
||||
public:
|
||||
void
|
||||
update(std::vector<LedgerObject> const& blobs, uint32_t seq);
|
||||
|
||||
std::optional<Blob>
|
||||
get(ripple::uint256 const& key, uint32_t seq) const;
|
||||
|
||||
std::optional<LedgerObject>
|
||||
getSuccessor(ripple::uint256 const& key, uint32_t seq) const;
|
||||
|
||||
std::optional<LedgerObject>
|
||||
getPredecessor(ripple::uint256 const& key, uint32_t seq) const;
|
||||
};
|
||||
|
||||
} // namespace Backend
|
||||
#endif
|
||||
@@ -2,6 +2,7 @@
|
||||
#include <boost/format.hpp>
|
||||
#include <backend/PostgresBackend.h>
|
||||
#include <thread>
|
||||
|
||||
namespace Backend {
|
||||
|
||||
// Type alias for async completion handlers
|
||||
@@ -77,6 +78,12 @@ PostgresBackend::writeAccountTransactions(
|
||||
}
|
||||
}
|
||||
|
||||
void
|
||||
PostgresBackend::writeNFTTransactions(std::vector<NFTTransactionsData>&& data)
|
||||
{
|
||||
throw std::runtime_error("Not implemented");
|
||||
}
|
||||
|
||||
void
|
||||
PostgresBackend::doWriteLedgerObject(
|
||||
std::string&& key,
|
||||
@@ -152,6 +159,12 @@ PostgresBackend::writeTransaction(
|
||||
<< '\t' << "\\\\x" << ripple::strHex(metadata) << '\n';
|
||||
}
|
||||
|
||||
void
|
||||
PostgresBackend::writeNFTs(std::vector<NFTsData>&& data)
|
||||
{
|
||||
throw std::runtime_error("Not implemented");
|
||||
}
|
||||
|
||||
std::uint32_t
|
||||
checkResult(PgResult const& res, std::uint32_t const numFieldsExpected)
|
||||
{
|
||||
@@ -419,6 +432,15 @@ PostgresBackend::fetchAllTransactionHashesInLedger(
|
||||
return {};
|
||||
}
|
||||
|
||||
std::optional<NFT>
|
||||
PostgresBackend::fetchNFT(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
throw std::runtime_error("Not implemented");
|
||||
}
|
||||
|
||||
std::optional<ripple::uint256>
|
||||
PostgresBackend::doFetchSuccessorKey(
|
||||
ripple::uint256 key,
|
||||
@@ -637,12 +659,25 @@ PostgresBackend::fetchLedgerDiff(
|
||||
return {};
|
||||
}
|
||||
|
||||
AccountTransactions
|
||||
// TODO this implementation and fetchAccountTransactions should be
|
||||
// generalized
|
||||
TransactionsAndCursor
|
||||
PostgresBackend::fetchNFTTransactions(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const limit,
|
||||
bool forward,
|
||||
std::optional<TransactionsCursor> const& cursor,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
throw std::runtime_error("Not implemented");
|
||||
}
|
||||
|
||||
TransactionsAndCursor
|
||||
PostgresBackend::fetchAccountTransactions(
|
||||
ripple::AccountID const& account,
|
||||
std::uint32_t const limit,
|
||||
bool forward,
|
||||
std::optional<AccountTransactionsCursor> const& cursor,
|
||||
std::optional<TransactionsCursor> const& cursor,
|
||||
boost::asio::yield_context& yield) const
|
||||
{
|
||||
PgQuery pgQuery(pgPool_);
|
||||
|
||||
@@ -62,6 +62,20 @@ public:
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
std::optional<NFT>
|
||||
fetchNFT(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const ledgerSequence,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
TransactionsAndCursor
|
||||
fetchNFTTransactions(
|
||||
ripple::uint256 const& tokenID,
|
||||
std::uint32_t const limit,
|
||||
bool const forward,
|
||||
std::optional<TransactionsCursor> const& cursorIn,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
std::vector<LedgerObject>
|
||||
fetchLedgerDiff(
|
||||
std::uint32_t const ledgerSequence,
|
||||
@@ -87,12 +101,12 @@ public:
|
||||
std::uint32_t const sequence,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
AccountTransactions
|
||||
TransactionsAndCursor
|
||||
fetchAccountTransactions(
|
||||
ripple::AccountID const& account,
|
||||
std::uint32_t const limit,
|
||||
bool forward,
|
||||
std::optional<AccountTransactionsCursor> const& cursor,
|
||||
std::optional<TransactionsCursor> const& cursor,
|
||||
boost::asio::yield_context& yield) const override;
|
||||
|
||||
void
|
||||
@@ -120,10 +134,16 @@ public:
|
||||
std::string&& transaction,
|
||||
std::string&& metadata) override;
|
||||
|
||||
void
|
||||
writeNFTs(std::vector<NFTsData>&& data) override;
|
||||
|
||||
void
|
||||
writeAccountTransactions(
|
||||
std::vector<AccountTransactionsData>&& data) override;
|
||||
|
||||
void
|
||||
writeNFTTransactions(std::vector<NFTTransactionsData>&& data) override;
|
||||
|
||||
void
|
||||
open(bool readOnly) override;
|
||||
|
||||
|
||||
@@ -1,174 +1,132 @@
|
||||
The data model used by clio is different than that used by rippled.
|
||||
rippled uses what is known as a SHAMap, which is a tree structure, with
|
||||
actual ledger and transaction data at the leaves of the tree. Looking up a record
|
||||
is a tree traversal, where the key is used to determine the path to the proper
|
||||
leaf node. The path from root to leaf is used as a proof-tree on the p2p network,
|
||||
where nodes can prove that a piece of data is present in a ledger by sending
|
||||
the path from root to leaf. Other nodes can verify this path and be certain
|
||||
that the data does actually exist in the ledger in question.
|
||||
# Clio Backend
|
||||
## Background
|
||||
The backend of Clio is responsible for handling the proper reading and writing of past ledger data from and to a given database. As of right now, Cassandra is the only supported database that is production-ready. However, support for more databases like PostgreSQL and DynamoDB may be added in future versions. Support for database types can be easily extended by creating new implementations which implements the virtual methods of `BackendInterface.h`. Then, use the Factory Object Design Pattern to simply add logic statements to `BackendFactory.h` that return the new database interface for a specific `type` in Clio's configuration file.
|
||||
|
||||
clio instead flattens the data model, so lookups are O(1). This results in time
|
||||
and space savings. This is possible because clio does not participate in the peer
|
||||
to peer protocol, and thus does not need to verify any data. clio fully trusts the
|
||||
rippled nodes that are being used as a data source.
|
||||
## Data Model
|
||||
The data model used by Clio to read and write ledger data is different from what Rippled uses. Rippled uses a novel data structure named [*SHAMap*](https://github.com/ripple/rippled/blob/master/src/ripple/shamap/README.md), which is a combination of a Merkle Tree and a Radix Trie. In a SHAMap, ledger objects are stored in the root vertices of the tree. Thus, looking up a record located at the leaf node of the SHAMap executes a tree search, where the path from the root node to the leaf node is the key of the record. Rippled nodes can also generate a proof-tree by forming a subtree with all the path nodes and their neighbors, which can then be used to prove the existnce of the leaf node data to other Rippled nodes. In short, the main purpose of the SHAMap data structure is to facilitate the fast validation of data integrity between different decentralized Rippled nodes.
|
||||
|
||||
clio uses certain features of database query languages to make this happen. Many
|
||||
databases provide the necessary features to implement the clio data model. At the
|
||||
time of writing, the data model is implemented in PostgreSQL and CQL (the query
|
||||
language used by Apache Cassandra and ScyllaDB).
|
||||
Since Clio only extracts past validated ledger data from a group of trusted Rippled nodes, it can be safely assumed that these ledger data are correct without the need to validate with other nodes in the XRP peer-to-peer network. Because of this, Clio is able to use a flattened data model to store the past validated ledger data, which allows for direct record lookup with much faster constant time operations.
|
||||
|
||||
The below examples are a sort of pseudo query language
|
||||
There are three main types of data in each XRP ledger version, they are [Ledger Header](https://xrpl.org/ledger-header.html), [Transaction Set](https://xrpl.org/transaction-formats.html) and [State Data](https://xrpl.org/ledger-object-types.html). Due to the structural differences of the different types of databases, Clio may choose to represent these data using a different schema for each unique database type.
|
||||
|
||||
## Ledgers
|
||||
**Keywords**
|
||||
*Sequence*: A unique incrementing identification number used to label the different ledger versions.
|
||||
*Hash*: The SHA512-half (calculate SHA512 and take the first 256 bits) hash of various ledger data like the entire ledger or specific ledger objects.
|
||||
*Ledger Object*: The [binary-encoded](https://xrpl.org/serialization.html) STObject containing specific data (i.e. metadata, transaction data).
|
||||
*Metadata*: The data containing [detailed information](https://xrpl.org/transaction-metadata.html#transaction-metadata) of the outcome of a specific transaction, regardless of whether the transaction was successful.
|
||||
*Transaction data*: The data containing the [full details](https://xrpl.org/transaction-common-fields.html) of a specific transaction.
|
||||
*Object Index*: The pseudo-random unique identifier of a ledger object, created by hashing the data of the object.
|
||||
|
||||
We store ledger headers in a ledgers table. In PostgreSQL, we store
|
||||
the headers in their deserialized form, so we can look up by sequence or hash.
|
||||
## Cassandra Implementation
|
||||
Cassandra is a distributed wide-column NoSQL database designed to handle large data throughput with high availability and no single point of failure. By leveraging Cassandra, Clio will be able to quickly and reliably scale up when needed simply by adding more Cassandra nodes to the Cassandra cluster configuration.
|
||||
|
||||
In Cassandra, we store the headers as blobs. The primary table maps a ledger sequence
|
||||
to the blob, and a secondary table maps a ledger hash to a ledger sequence.
|
||||
In Cassandra, Clio will be creating 9 tables to store the ledger data, they are `ledger_transactions`, `transactions`, `ledger_hashes`, `ledger_range`, `objects`, `ledgers`, `diff`, `account_tx`, and `successor`. Their schemas and how they work are detailed below.
|
||||
|
||||
## Transactions
|
||||
Transactions are stored in a very basic table, with a schema like so:
|
||||
*Note, if you would like visually explore the data structure of the Cassandra database, you can first run Clio server with database `type` configured as `cassandra` to fill ledger data from Rippled nodes into Cassandra, then use a GUI database management tool like [Datastax's Opcenter](https://docs.datastax.com/en/install/6.0/install/opscInstallOpsc.html) to interactively view it.*
|
||||
|
||||
|
||||
### `ledger_transactions`
|
||||
```
|
||||
CREATE TABLE transactions (
|
||||
hash blob,
|
||||
ledger_sequence int,
|
||||
transaction blob,
|
||||
PRIMARY KEY(hash))
|
||||
CREATE TABLE clio.ledger_transactions (
|
||||
ledger_sequence bigint, # The sequence number of the ledger version
|
||||
hash blob, # Hash of all the transactions on this ledger version
|
||||
PRIMARY KEY (ledger_sequence, hash)
|
||||
) WITH CLUSTERING ORDER BY (hash ASC) ...
|
||||
```
|
||||
This table stores the hashes of all transactions in a given ledger sequence ordered by the hash value in ascending order.
|
||||
|
||||
### `transactions`
|
||||
```
|
||||
The primary key is the hash.
|
||||
CREATE TABLE clio.transactions (
|
||||
hash blob PRIMARY KEY, # The transaction hash
|
||||
date bigint, # Date of the transaction
|
||||
ledger_sequence bigint, # The sequence that the transaction was validated
|
||||
metadata blob, # Metadata of the transaction
|
||||
transaction blob # Data of the transaction
|
||||
) ...
|
||||
```
|
||||
This table stores the full transaction and metadata of each ledger version with the transaction hash as the primary key.
|
||||
|
||||
A common query pattern is fetching all transactions in a ledger. In PostgreSQL,
|
||||
nothing special is needed for this. We just query:
|
||||
To look up all the transactions that were validated in a ledger version with sequence `n`, one can first get the all the transaction hashes in that ledger version by querying `SELECT * FROM ledger_transactions WHERE ledger_sequence = n;`. Then, iterate through the list of hashes and query `SELECT * FROM transactions WHERE hash = one_of_the_hash_from_the_list;` to get the detailed transaction data.
|
||||
|
||||
### `ledger_hashes`
|
||||
```
|
||||
SELECT * FROM transactions WHERE ledger_sequence = s;
|
||||
CREATE TABLE clio.ledger_hashes (
|
||||
hash blob PRIMARY KEY, # Hash of entire ledger version's data
|
||||
sequence bigint # The sequence of the ledger version
|
||||
) ...
|
||||
```
|
||||
This table stores the hash of all ledger versions by their sequences.
|
||||
### `ledger_range`
|
||||
```
|
||||
Cassandra doesn't handle queries like this well, since `ledger_sequence` is not
|
||||
the primary key, so we use a second table that maps a ledger sequence number
|
||||
to all of the hashes in that ledger:
|
||||
CREATE TABLE clio.ledger_range (
|
||||
is_latest boolean PRIMARY KEY, # Whether this sequence is the stopping range
|
||||
sequence bigint # The sequence number of the starting/stopping range
|
||||
) ...
|
||||
```
|
||||
This table marks the range of ledger versions that is stored on this specific Cassandra node. Because of its nature, there are only two records in this table with `false` and `true` values for `is_latest`, marking the starting and ending sequence of the ledger range.
|
||||
|
||||
### `objects`
|
||||
```
|
||||
CREATE TABLE transaction_hashes (
|
||||
ledger_sequence int,
|
||||
hash blob,
|
||||
PRIMARY KEY(ledger_sequence, blob))
|
||||
CREATE TABLE clio.objects (
|
||||
key blob, # Object index of the object
|
||||
sequence bigint, # The sequence this object was last updated
|
||||
object blob, # Data of the object
|
||||
PRIMARY KEY (key, sequence)
|
||||
) WITH CLUSTERING ORDER BY (sequence DESC) ...
|
||||
```
|
||||
This table stores the specific data of all objects that ever existed on the XRP network, even if they are deleted (which is represented with a special `0x` value). The records are ordered by descending sequence, where the newest validated ledger objects are at the top.
|
||||
|
||||
This table is updated when all data for a given ledger sequence has been written to the various tables in the database. For each ledger, many associated records are written to different tables. This table is used as a synchronization mechanism, to prevent the application from reading data from a ledger for which all data has not yet been fully written.
|
||||
|
||||
### `ledgers`
|
||||
```
|
||||
This table uses a compound primary key, so we can have multiple records with
|
||||
the same ledger sequence but different hash. Looking up all of the transactions
|
||||
in a given ledger then requires querying the transaction_hashes table to get the hashes of
|
||||
all of the transactions in the ledger, and then using those hashes to query the
|
||||
transactions table. Sometimes we only want the hashes though.
|
||||
|
||||
## Ledger data
|
||||
|
||||
Ledger data is more complicated than transaction data. Objects have different versions,
|
||||
where applying transactions in a particular ledger changes an object with a given
|
||||
key. A basic example is an account root object: the balance changes with every
|
||||
transaction sent or received, though the key (object ID) for this object remains the same.
|
||||
|
||||
Ledger data then is modeled like so:
|
||||
CREATE TABLE clio.ledgers (
|
||||
sequence bigint PRIMARY KEY, # Sequence of the ledger version
|
||||
header blob # Data of the header
|
||||
) ...
|
||||
```
|
||||
This table stores the ledger header data of specific ledger versions by their sequence.
|
||||
|
||||
### `diff`
|
||||
```
|
||||
CREATE TABLE objects (
|
||||
id blob,
|
||||
ledger_sequence int,
|
||||
object blob,
|
||||
PRIMARY KEY(key,ledger_sequence))
|
||||
CREATE TABLE clio.diff (
|
||||
seq bigint, # Sequence of the ledger version
|
||||
key blob, # Hash of changes in the ledger version
|
||||
PRIMARY KEY (seq, key)
|
||||
) WITH CLUSTERING ORDER BY (key ASC) ...
|
||||
```
|
||||
This table stores the object index of all the changes in each ledger version.
|
||||
|
||||
### `account_tx`
|
||||
```
|
||||
CREATE TABLE clio.account_tx (
|
||||
account blob,
|
||||
seq_idx frozen<tuple<bigint, bigint>>, # Tuple of (ledger_index, transaction_index)
|
||||
hash blob, # Hash of the transaction
|
||||
PRIMARY KEY (account, seq_idx)
|
||||
) WITH CLUSTERING ORDER BY (seq_idx DESC) ...
|
||||
```
|
||||
This table stores the list of transactions affecting a given account. This includes transactions made by the account, as well as transactions received.
|
||||
|
||||
The `objects` table has a compound primary key. This is essential. Looking up
|
||||
a ledger object as of a given ledger then is just:
|
||||
|
||||
### `successor`
|
||||
```
|
||||
SELECT object FROM objects WHERE id = ? and ledger_sequence <= ?
|
||||
ORDER BY ledger_sequence DESC LIMIT 1;
|
||||
```
|
||||
This gives us the most recent ledger object written at or before a specified ledger.
|
||||
CREATE TABLE clio.successor (
|
||||
key blob, # Object index
|
||||
seq bigint, # The sequnce that this ledger object's predecessor and successor was updated
|
||||
next blob, # Index of the next object that existed in this sequence
|
||||
PRIMARY KEY (key, seq)
|
||||
) WITH CLUSTERING ORDER BY (seq ASC) ...
|
||||
```
|
||||
This table is the important backbone of how histories of ledger objects are stored in Cassandra. The successor table stores the object index of all ledger objects that were validated on the XRP network along with the ledger sequence that the object was upated on. Due to the unique nature of the table with each key being ordered by the sequence, by tracing through the table with a specific sequence number, Clio can recreate a Linked List data structure that represents all the existing ledger object at that ledger sequence. The special value of `0x00...00` and `0xFF...FF` are used to label the head and tail of the Linked List in the successor table. The diagram below showcases how tracing through the same table but with different sequence parameter filtering can result in different Linked List data representing the corresponding past state of the ledger objects. A query like `SELECT * FROM successor WHERE key = ? AND seq <= n ORDER BY seq DESC LIMIT 1;` can effectively trace through the successor table and get the Linked List of a specific sequence `n`.
|
||||
|
||||
When a ledger object is deleted, we write a record where `object` is just an empty blob.
|
||||
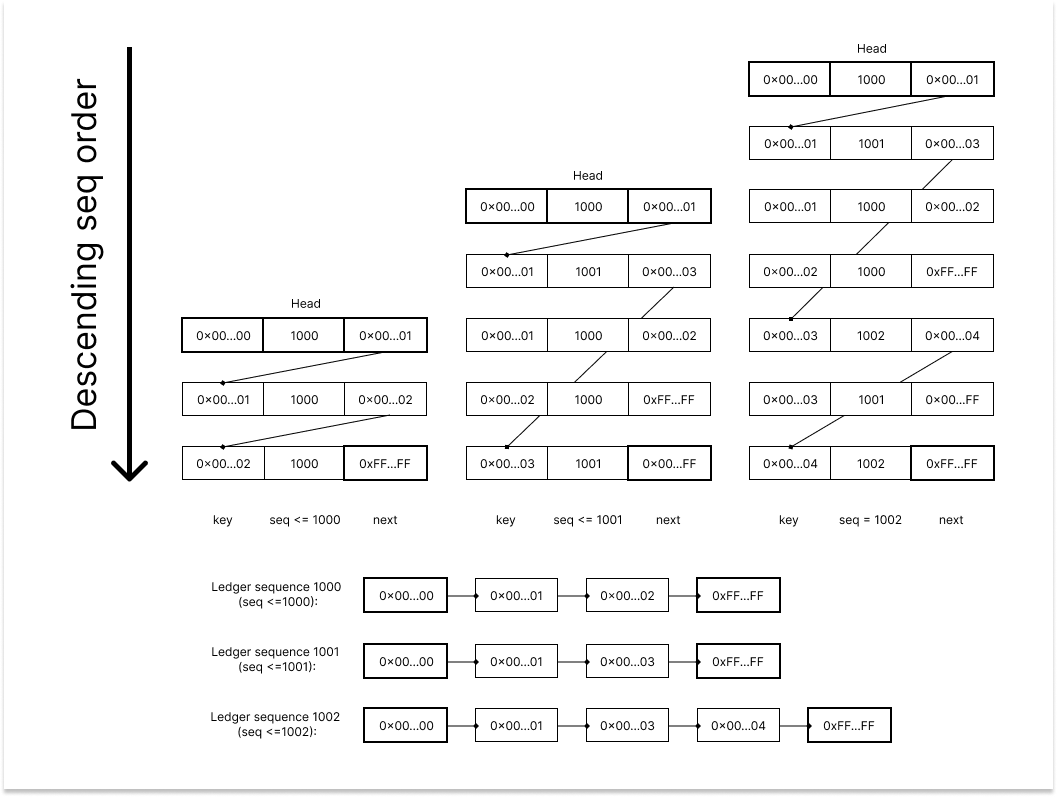
|
||||
*P.S.: The `diff` is `(DELETE 0x00...02, CREATE 0x00...03)` for `seq=1001` and `(CREATE 0x00...04)` for `seq=1002`, which is both accurately reflected with the Linked List trace*
|
||||
|
||||
### Next
|
||||
Generally RPCs that read ledger data will just use the above query pattern. However,
|
||||
a few RPCs (`book_offers` and `ledger_data`) make use of a certain tree operation
|
||||
called `successor`, which takes in an object id and ledger sequence, and returns
|
||||
the id of the successor object in the ledger. This is the object in the ledger with the smallest id
|
||||
greater than the input id.
|
||||
|
||||
This problem is quite difficult for clio's data model, since computing this
|
||||
generally requires the inner nodes of the tree, which clio doesn't store. A naive
|
||||
way to do this with PostgreSQL is like so:
|
||||
```
|
||||
SELECT * FROM objects WHERE id > ? AND ledger_sequence <= s ORDER BY id ASC, ledger_sequence DESC LIMIT 1;
|
||||
```
|
||||
This query is not really possible with Cassandra, unless you use ALLOW FILTERING, which
|
||||
is an anti pattern (for good reason!). It would require contacting basically every node
|
||||
in the entire cluster.
|
||||
|
||||
But even with Postgres, this query is not scalable. Why? Consider what the query
|
||||
is doing at the database level. The database starts at the input id, and begins scanning
|
||||
the table in ascending order of id. It needs to skip over any records that don't actually
|
||||
exist in the desired ledger, which are objects that have been deleted, or objects that
|
||||
were created later. As ledger history grows, this query skips over more and more records,
|
||||
which results in the query taking longer and longer. The time this query takes grows
|
||||
unbounded then, as ledger history just keeps growing. With under a million ledgers, this
|
||||
query is usable, but as we approach 10 million ledgers are more, the query starts to become very slow.
|
||||
|
||||
To alleviate this issue, the data model uses a checkpointing method. We create a second
|
||||
table called keys, like so:
|
||||
```
|
||||
CREATE TABLE keys (
|
||||
ledger_sequence int,
|
||||
id blob,
|
||||
PRIMARY KEY(ledger_sequence, id)
|
||||
)
|
||||
```
|
||||
However, this table does not have an entry for every ledger sequence. Instead,
|
||||
this table has an entry for rougly every 1 million ledgers. We call these ledgers
|
||||
flag ledgers. For each flag ledger, the keys table contains every object id in that
|
||||
ledger, as well as every object id that existed in any ledger between the last flag
|
||||
ledger and this one. This is a lot of keys, but not every key that ever existed (which
|
||||
is what the naive attempt at implementing successor was iterating over). In this manner,
|
||||
the performance is bounded. If we wanted to increase the performance of the successor operation,
|
||||
we can increase the frequency of flag ledgers. However, this will use more space. 1 million
|
||||
was chosen as a reasonable tradeoff to bound the performance, but not use too much space,
|
||||
especially since this is only needed for two RPC calls.
|
||||
|
||||
We write to this table every ledger, for each new key. However, we also need to handle
|
||||
keys that existed in the previous flag ledger. To do that, at each flag ledger, we
|
||||
iterate through the previous flag ledger, and write any keys that are still present
|
||||
in the new flag ledger. This is done asynchronously.
|
||||
|
||||
## Account Transactions
|
||||
rippled offers a RPC called `account_tx`. This RPC returns all transactions that
|
||||
affect a given account, and allows users to page backwards or forwards in time.
|
||||
Generally, this is a modeled with a table like so:
|
||||
```
|
||||
CREATE TABLE account_tx (
|
||||
account blob,
|
||||
ledger_sequence int,
|
||||
transaction_index int,
|
||||
hash blob,
|
||||
PRIMARY KEY(account,ledger_sequence,transaction_index))
|
||||
```
|
||||
|
||||
An example of looking up from this table going backwards in time is:
|
||||
```
|
||||
SELECT hash FROM account_tx WHERE account = ?
|
||||
AND ledger_sequence <= ? and transaction_index <= ?
|
||||
ORDER BY ledger_sequence DESC, transaction_index DESC;
|
||||
```
|
||||
|
||||
This query returns the hashes, and then we use those hashes to read from the
|
||||
transactions table.
|
||||
|
||||
## Comments
|
||||
There are various nuances around how these data models are tuned and optimized
|
||||
for each database implementation. Cassandra and PostgreSQL are very different,
|
||||
so some slight modifications are needed. However, the general model outlined here
|
||||
is implemented by both databases, and when adding a new database, this general model
|
||||
should be followed, unless there is a good reason not to. Generally, a database will be
|
||||
decently similar to either PostgreSQL or Cassandra, so using those as a basis should
|
||||
be sufficient.
|
||||
|
||||
Whatever database is used, clio requires strong consistency, and durability. For this
|
||||
reason, any replication strategy needs to maintain strong consistency.
|
||||
In each new ledger version with sequence `n`, a ledger object `v` can either be **created**, **modified**, or **deleted**. For all three of these operations, the procedure to update the successor table can be broken down in to two steps:
|
||||
1. Trace through the Linked List of the previous sequence to to find the ledger object `e` with the greatest object index smaller or equal than the `v`'s index. Save `e`'s `next` value (the index of the next ledger object) as `w`.
|
||||
2. If `v` is...
|
||||
1. Being **created**, add two new records of `seq=n` with one being `e` pointing to `v`, and `v` pointing to `w` (Linked List insertion operation).
|
||||
2. Being **modified**, do nothing.
|
||||
3. Being **deleted**, add a record of `seq=n` with `e` pointing to `v`'s `next` value (Linked List deletion operation).
|
||||
@@ -1,6 +1,7 @@
|
||||
#ifndef CLIO_TYPES_H_INCLUDED
|
||||
#define CLIO_TYPES_H_INCLUDED
|
||||
#include <ripple/basics/base_uint.h>
|
||||
#include <ripple/protocol/AccountID.h>
|
||||
#include <optional>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
@@ -46,16 +47,34 @@ struct TransactionAndMetadata
|
||||
}
|
||||
};
|
||||
|
||||
struct AccountTransactionsCursor
|
||||
struct TransactionsCursor
|
||||
{
|
||||
std::uint32_t ledgerSequence;
|
||||
std::uint32_t transactionIndex;
|
||||
};
|
||||
|
||||
struct AccountTransactions
|
||||
struct TransactionsAndCursor
|
||||
{
|
||||
std::vector<TransactionAndMetadata> txns;
|
||||
std::optional<AccountTransactionsCursor> cursor;
|
||||
std::optional<TransactionsCursor> cursor;
|
||||
};
|
||||
|
||||
struct NFT
|
||||
{
|
||||
ripple::uint256 tokenID;
|
||||
std::uint32_t ledgerSequence;
|
||||
ripple::AccountID owner;
|
||||
bool isBurned;
|
||||
|
||||
// clearly two tokens are the same if they have the same ID, but this
|
||||
// struct stores the state of a given token at a given ledger sequence, so
|
||||
// we also need to compare with ledgerSequence
|
||||
bool
|
||||
operator==(NFT const& other) const
|
||||
{
|
||||
return tokenID == other.tokenID &&
|
||||
ledgerSequence == other.ledgerSequence;
|
||||
}
|
||||
};
|
||||
|
||||
struct LedgerRange
|
||||
|
||||
@@ -174,4 +174,4 @@ getMarkers(size_t numMarkers)
|
||||
return markers;
|
||||
}
|
||||
|
||||
#endif // RIPPLE_APP_REPORTING_ETLHELPERS_H_INCLUDED
|
||||
#endif // RIPPLE_APP_REPORTING_ETLHELPERS_H_INCLUDED
|
||||
|
||||
@@ -1032,7 +1032,7 @@ ETLLoadBalancer::fetchLedger(
|
||||
auto [status, data] = source->fetchLedger(
|
||||
ledgerSequence, getObjects, getObjectNeighbors);
|
||||
response = std::move(data);
|
||||
if (status.ok() && (response.validated() || true))
|
||||
if (status.ok() && response.validated())
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(info)
|
||||
<< "Successfully fetched ledger = " << ledgerSequence
|
||||
|
||||
370
src/etl/NFTHelpers.cpp
Normal file
370
src/etl/NFTHelpers.cpp
Normal file
@@ -0,0 +1,370 @@
|
||||
#include <ripple/app/tx/impl/details/NFTokenUtils.h>
|
||||
#include <ripple/protocol/STBase.h>
|
||||
#include <ripple/protocol/STTx.h>
|
||||
#include <ripple/protocol/TxMeta.h>
|
||||
#include <vector>
|
||||
|
||||
#include <backend/BackendInterface.h>
|
||||
#include <backend/DBHelpers.h>
|
||||
#include <backend/Types.h>
|
||||
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTokenMintData(ripple::TxMeta const& txMeta, ripple::STTx const& sttx)
|
||||
{
|
||||
// To find the minted token ID, we put all tokenIDs referenced in the
|
||||
// metadata from prior to the tx application into one vector, then all
|
||||
// tokenIDs referenced in the metadata from after the tx application into
|
||||
// another, then find the one tokenID that was added by this tx
|
||||
// application.
|
||||
std::vector<ripple::uint256> prevIDs;
|
||||
std::vector<ripple::uint256> finalIDs;
|
||||
|
||||
// The owner is not necessarily the issuer, if using authorized minter
|
||||
// flow. Determine owner from the ledger object ID of the NFTokenPages
|
||||
// that were changed.
|
||||
std::optional<ripple::AccountID> owner;
|
||||
|
||||
for (ripple::STObject const& node : txMeta.getNodes())
|
||||
{
|
||||
if (node.getFieldU16(ripple::sfLedgerEntryType) !=
|
||||
ripple::ltNFTOKEN_PAGE)
|
||||
continue;
|
||||
|
||||
if (!owner)
|
||||
owner = ripple::AccountID::fromVoid(
|
||||
node.getFieldH256(ripple::sfLedgerIndex).data());
|
||||
|
||||
if (node.getFName() == ripple::sfCreatedNode)
|
||||
{
|
||||
ripple::STArray const& toAddNFTs =
|
||||
node.peekAtField(ripple::sfNewFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldArray(ripple::sfNFTokens);
|
||||
std::transform(
|
||||
toAddNFTs.begin(),
|
||||
toAddNFTs.end(),
|
||||
std::back_inserter(finalIDs),
|
||||
[](ripple::STObject const& nft) {
|
||||
return nft.getFieldH256(ripple::sfNFTokenID);
|
||||
});
|
||||
}
|
||||
// Else it's modified, as there should never be a deleted NFToken page
|
||||
// as a result of a mint.
|
||||
else
|
||||
{
|
||||
// When a mint results in splitting an existing page,
|
||||
// it results in a created page and a modified node. Sometimes,
|
||||
// the created node needs to be linked to a third page, resulting
|
||||
// in modifying that third page's PreviousPageMin or NextPageMin
|
||||
// field changing, but no NFTs within that page changing. In this
|
||||
// case, there will be no previous NFTs and we need to skip.
|
||||
// However, there will always be NFTs listed in the final fields,
|
||||
// as rippled outputs all fields in final fields even if they were
|
||||
// not changed.
|
||||
ripple::STObject const& previousFields =
|
||||
node.peekAtField(ripple::sfPreviousFields)
|
||||
.downcast<ripple::STObject>();
|
||||
if (!previousFields.isFieldPresent(ripple::sfNFTokens))
|
||||
continue;
|
||||
|
||||
ripple::STArray const& toAddNFTs =
|
||||
previousFields.getFieldArray(ripple::sfNFTokens);
|
||||
std::transform(
|
||||
toAddNFTs.begin(),
|
||||
toAddNFTs.end(),
|
||||
std::back_inserter(prevIDs),
|
||||
[](ripple::STObject const& nft) {
|
||||
return nft.getFieldH256(ripple::sfNFTokenID);
|
||||
});
|
||||
|
||||
ripple::STArray const& toAddFinalNFTs =
|
||||
node.peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldArray(ripple::sfNFTokens);
|
||||
std::transform(
|
||||
toAddFinalNFTs.begin(),
|
||||
toAddFinalNFTs.end(),
|
||||
std::back_inserter(finalIDs),
|
||||
[](ripple::STObject const& nft) {
|
||||
return nft.getFieldH256(ripple::sfNFTokenID);
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
std::sort(finalIDs.begin(), finalIDs.end());
|
||||
std::sort(prevIDs.begin(), prevIDs.end());
|
||||
std::vector<ripple::uint256> tokenIDResult;
|
||||
std::set_difference(
|
||||
finalIDs.begin(),
|
||||
finalIDs.end(),
|
||||
prevIDs.begin(),
|
||||
prevIDs.end(),
|
||||
std::inserter(tokenIDResult, tokenIDResult.begin()));
|
||||
if (tokenIDResult.size() == 1 && owner)
|
||||
return {
|
||||
{NFTTransactionsData(
|
||||
tokenIDResult.front(), txMeta, sttx.getTransactionID())},
|
||||
NFTsData(tokenIDResult.front(), *owner, txMeta, false)};
|
||||
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - unexpected NFTokenMint data in tx "
|
||||
<< sttx.getTransactionID();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTokenBurnData(ripple::TxMeta const& txMeta, ripple::STTx const& sttx)
|
||||
{
|
||||
ripple::uint256 const tokenID = sttx.getFieldH256(ripple::sfNFTokenID);
|
||||
std::vector<NFTTransactionsData> const txs = {
|
||||
NFTTransactionsData(tokenID, txMeta, sttx.getTransactionID())};
|
||||
|
||||
// Determine who owned the token when it was burned by finding an
|
||||
// NFTokenPage that was deleted or modified that contains this
|
||||
// tokenID.
|
||||
for (ripple::STObject const& node : txMeta.getNodes())
|
||||
{
|
||||
if (node.getFieldU16(ripple::sfLedgerEntryType) !=
|
||||
ripple::ltNFTOKEN_PAGE ||
|
||||
node.getFName() == ripple::sfCreatedNode)
|
||||
continue;
|
||||
|
||||
// NFT burn can result in an NFTokenPage being modified to no longer
|
||||
// include the target, or an NFTokenPage being deleted. If this is
|
||||
// modified, we want to look for the target in the fields prior to
|
||||
// modification. If deleted, it's possible that the page was modified
|
||||
// to remove the target NFT prior to the entire page being deleted. In
|
||||
// this case, we need to look in the PreviousFields. Otherwise, the
|
||||
// page was not modified prior to deleting and we need to look in the
|
||||
// FinalFields.
|
||||
std::optional<ripple::STArray> prevNFTs;
|
||||
|
||||
if (node.isFieldPresent(ripple::sfPreviousFields))
|
||||
{
|
||||
ripple::STObject const& previousFields =
|
||||
node.peekAtField(ripple::sfPreviousFields)
|
||||
.downcast<ripple::STObject>();
|
||||
if (previousFields.isFieldPresent(ripple::sfNFTokens))
|
||||
prevNFTs = previousFields.getFieldArray(ripple::sfNFTokens);
|
||||
}
|
||||
else if (!prevNFTs && node.getFName() == ripple::sfDeletedNode)
|
||||
prevNFTs = node.peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldArray(ripple::sfNFTokens);
|
||||
|
||||
if (!prevNFTs)
|
||||
continue;
|
||||
|
||||
auto const nft = std::find_if(
|
||||
prevNFTs->begin(),
|
||||
prevNFTs->end(),
|
||||
[&tokenID](ripple::STObject const& candidate) {
|
||||
return candidate.getFieldH256(ripple::sfNFTokenID) == tokenID;
|
||||
});
|
||||
if (nft != prevNFTs->end())
|
||||
return std::make_pair(
|
||||
txs,
|
||||
NFTsData(
|
||||
tokenID,
|
||||
ripple::AccountID::fromVoid(
|
||||
node.getFieldH256(ripple::sfLedgerIndex).data()),
|
||||
txMeta,
|
||||
true));
|
||||
}
|
||||
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - could not determine owner at burntime for tx "
|
||||
<< sttx.getTransactionID();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTokenAcceptOfferData(
|
||||
ripple::TxMeta const& txMeta,
|
||||
ripple::STTx const& sttx)
|
||||
{
|
||||
// If we have the buy offer from this tx, we can determine the owner
|
||||
// more easily by just looking at the owner of the accepted NFTokenOffer
|
||||
// object.
|
||||
if (sttx.isFieldPresent(ripple::sfNFTokenBuyOffer))
|
||||
{
|
||||
auto const affectedBuyOffer = std::find_if(
|
||||
txMeta.getNodes().begin(),
|
||||
txMeta.getNodes().end(),
|
||||
[&sttx](ripple::STObject const& node) {
|
||||
return node.getFieldH256(ripple::sfLedgerIndex) ==
|
||||
sttx.getFieldH256(ripple::sfNFTokenBuyOffer);
|
||||
});
|
||||
if (affectedBuyOffer == txMeta.getNodes().end())
|
||||
{
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - unexpected NFTokenAcceptOffer data in tx "
|
||||
<< sttx.getTransactionID();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
|
||||
ripple::uint256 const tokenID =
|
||||
affectedBuyOffer->peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldH256(ripple::sfNFTokenID);
|
||||
|
||||
ripple::AccountID const owner =
|
||||
affectedBuyOffer->peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getAccountID(ripple::sfOwner);
|
||||
return {
|
||||
{NFTTransactionsData(tokenID, txMeta, sttx.getTransactionID())},
|
||||
NFTsData(tokenID, owner, txMeta, false)};
|
||||
}
|
||||
|
||||
// Otherwise we have to infer the new owner from the affected nodes.
|
||||
auto const affectedSellOffer = std::find_if(
|
||||
txMeta.getNodes().begin(),
|
||||
txMeta.getNodes().end(),
|
||||
[&sttx](ripple::STObject const& node) {
|
||||
return node.getFieldH256(ripple::sfLedgerIndex) ==
|
||||
sttx.getFieldH256(ripple::sfNFTokenSellOffer);
|
||||
});
|
||||
if (affectedSellOffer == txMeta.getNodes().end())
|
||||
{
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - unexpected NFTokenAcceptOffer data in tx "
|
||||
<< sttx.getTransactionID();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
|
||||
ripple::uint256 const tokenID =
|
||||
affectedSellOffer->peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldH256(ripple::sfNFTokenID);
|
||||
|
||||
ripple::AccountID const seller =
|
||||
affectedSellOffer->peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getAccountID(ripple::sfOwner);
|
||||
|
||||
for (ripple::STObject const& node : txMeta.getNodes())
|
||||
{
|
||||
if (node.getFieldU16(ripple::sfLedgerEntryType) !=
|
||||
ripple::ltNFTOKEN_PAGE ||
|
||||
node.getFName() == ripple::sfDeletedNode)
|
||||
continue;
|
||||
|
||||
ripple::AccountID const nodeOwner = ripple::AccountID::fromVoid(
|
||||
node.getFieldH256(ripple::sfLedgerIndex).data());
|
||||
if (nodeOwner == seller)
|
||||
continue;
|
||||
|
||||
ripple::STArray const& nfts = [&node] {
|
||||
if (node.getFName() == ripple::sfCreatedNode)
|
||||
return node.peekAtField(ripple::sfNewFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldArray(ripple::sfNFTokens);
|
||||
return node.peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldArray(ripple::sfNFTokens);
|
||||
}();
|
||||
|
||||
auto const nft = std::find_if(
|
||||
nfts.begin(),
|
||||
nfts.end(),
|
||||
[&tokenID](ripple::STObject const& candidate) {
|
||||
return candidate.getFieldH256(ripple::sfNFTokenID) == tokenID;
|
||||
});
|
||||
if (nft != nfts.end())
|
||||
return {
|
||||
{NFTTransactionsData(tokenID, txMeta, sttx.getTransactionID())},
|
||||
NFTsData(tokenID, nodeOwner, txMeta, false)};
|
||||
}
|
||||
|
||||
std::stringstream msg;
|
||||
msg << __func__ << " - unexpected NFTokenAcceptOffer data in tx "
|
||||
<< sttx.getTransactionID();
|
||||
throw std::runtime_error(msg.str());
|
||||
}
|
||||
|
||||
// This is the only transaction where there can be more than 1 element in
|
||||
// the returned vector, because you can cancel multiple offers in one
|
||||
// transaction using this feature. This transaction also never returns an
|
||||
// NFTsData because it does not change the state of an NFT itself.
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTokenCancelOfferData(
|
||||
ripple::TxMeta const& txMeta,
|
||||
ripple::STTx const& sttx)
|
||||
{
|
||||
std::vector<NFTTransactionsData> txs;
|
||||
for (ripple::STObject const& node : txMeta.getNodes())
|
||||
{
|
||||
if (node.getFieldU16(ripple::sfLedgerEntryType) !=
|
||||
ripple::ltNFTOKEN_OFFER)
|
||||
continue;
|
||||
|
||||
ripple::uint256 const tokenID = node.peekAtField(ripple::sfFinalFields)
|
||||
.downcast<ripple::STObject>()
|
||||
.getFieldH256(ripple::sfNFTokenID);
|
||||
txs.emplace_back(tokenID, txMeta, sttx.getTransactionID());
|
||||
}
|
||||
|
||||
// Deduplicate any transactions based on tokenID/txIdx combo. Can't just
|
||||
// use txIdx because in this case one tx can cancel offers for several
|
||||
// NFTs.
|
||||
std::sort(
|
||||
txs.begin(),
|
||||
txs.end(),
|
||||
[](NFTTransactionsData const& a, NFTTransactionsData const& b) {
|
||||
return a.tokenID < b.tokenID &&
|
||||
a.transactionIndex < b.transactionIndex;
|
||||
});
|
||||
auto last = std::unique(
|
||||
txs.begin(),
|
||||
txs.end(),
|
||||
[](NFTTransactionsData const& a, NFTTransactionsData const& b) {
|
||||
return a.tokenID == b.tokenID &&
|
||||
a.transactionIndex == b.transactionIndex;
|
||||
});
|
||||
txs.erase(last, txs.end());
|
||||
return {txs, {}};
|
||||
}
|
||||
|
||||
// This transaction never returns an NFTokensData because it does not
|
||||
// change the state of an NFT itself.
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTokenCreateOfferData(
|
||||
ripple::TxMeta const& txMeta,
|
||||
ripple::STTx const& sttx)
|
||||
{
|
||||
return {
|
||||
{NFTTransactionsData(
|
||||
sttx.getFieldH256(ripple::sfNFTokenID),
|
||||
txMeta,
|
||||
sttx.getTransactionID())},
|
||||
{}};
|
||||
}
|
||||
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTData(ripple::TxMeta const& txMeta, ripple::STTx const& sttx)
|
||||
{
|
||||
if (txMeta.getResultTER() != ripple::tesSUCCESS)
|
||||
return {{}, {}};
|
||||
|
||||
switch (sttx.getTxnType())
|
||||
{
|
||||
case ripple::TxType::ttNFTOKEN_MINT:
|
||||
return getNFTokenMintData(txMeta, sttx);
|
||||
|
||||
case ripple::TxType::ttNFTOKEN_BURN:
|
||||
return getNFTokenBurnData(txMeta, sttx);
|
||||
|
||||
case ripple::TxType::ttNFTOKEN_ACCEPT_OFFER:
|
||||
return getNFTokenAcceptOfferData(txMeta, sttx);
|
||||
|
||||
case ripple::TxType::ttNFTOKEN_CANCEL_OFFER:
|
||||
return getNFTokenCancelOfferData(txMeta, sttx);
|
||||
|
||||
case ripple::TxType::ttNFTOKEN_CREATE_OFFER:
|
||||
return getNFTokenCreateOfferData(txMeta, sttx);
|
||||
|
||||
default:
|
||||
return {{}, {}};
|
||||
}
|
||||
}
|
||||
@@ -28,12 +28,13 @@ toString(ripple::LedgerInfo const& info)
|
||||
}
|
||||
} // namespace detail
|
||||
|
||||
std::vector<AccountTransactionsData>
|
||||
FormattedTransactionsData
|
||||
ReportingETL::insertTransactions(
|
||||
ripple::LedgerInfo const& ledger,
|
||||
org::xrpl::rpc::v1::GetLedgerResponse& data)
|
||||
{
|
||||
std::vector<AccountTransactionsData> accountTxData;
|
||||
FormattedTransactionsData result;
|
||||
|
||||
for (auto& txn :
|
||||
*(data.mutable_transactions_list()->mutable_transactions()))
|
||||
{
|
||||
@@ -42,21 +43,22 @@ ReportingETL::insertTransactions(
|
||||
ripple::SerialIter it{raw->data(), raw->size()};
|
||||
ripple::STTx sttx{it};
|
||||
|
||||
auto txSerializer =
|
||||
std::make_shared<ripple::Serializer>(sttx.getSerializer());
|
||||
|
||||
ripple::TxMeta txMeta{
|
||||
sttx.getTransactionID(), ledger.seq, txn.metadata_blob()};
|
||||
|
||||
auto metaSerializer = std::make_shared<ripple::Serializer>(
|
||||
txMeta.getAsObject().getSerializer());
|
||||
|
||||
BOOST_LOG_TRIVIAL(trace)
|
||||
<< __func__ << " : "
|
||||
<< "Inserting transaction = " << sttx.getTransactionID();
|
||||
|
||||
ripple::TxMeta txMeta{
|
||||
sttx.getTransactionID(), ledger.seq, txn.metadata_blob()};
|
||||
|
||||
auto const [nftTxs, maybeNFT] = getNFTData(txMeta, sttx);
|
||||
result.nfTokenTxData.insert(
|
||||
result.nfTokenTxData.end(), nftTxs.begin(), nftTxs.end());
|
||||
if (maybeNFT)
|
||||
result.nfTokensData.push_back(*maybeNFT);
|
||||
|
||||
auto journal = ripple::debugLog();
|
||||
accountTxData.emplace_back(txMeta, sttx.getTransactionID(), journal);
|
||||
result.accountTxData.emplace_back(
|
||||
txMeta, sttx.getTransactionID(), journal);
|
||||
std::string keyStr{(const char*)sttx.getTransactionID().data(), 32};
|
||||
backend_->writeTransaction(
|
||||
std::move(keyStr),
|
||||
@@ -65,7 +67,27 @@ ReportingETL::insertTransactions(
|
||||
std::move(*raw),
|
||||
std::move(*txn.mutable_metadata_blob()));
|
||||
}
|
||||
return accountTxData;
|
||||
|
||||
// Remove all but the last NFTsData for each id. unique removes all
|
||||
// but the first of a group, so we want to reverse sort by transaction
|
||||
// index
|
||||
std::sort(
|
||||
result.nfTokensData.begin(),
|
||||
result.nfTokensData.end(),
|
||||
[](NFTsData const& a, NFTsData const& b) {
|
||||
return a.tokenID > b.tokenID &&
|
||||
a.transactionIndex > b.transactionIndex;
|
||||
});
|
||||
// Now we can unique the NFTs by tokenID.
|
||||
auto last = std::unique(
|
||||
result.nfTokensData.begin(),
|
||||
result.nfTokensData.end(),
|
||||
[](NFTsData const& a, NFTsData const& b) {
|
||||
return a.tokenID == b.tokenID;
|
||||
});
|
||||
result.nfTokensData.erase(last, result.nfTokensData.end());
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
std::optional<ripple::LedgerInfo>
|
||||
@@ -106,7 +128,7 @@ ReportingETL::loadInitialLedger(uint32_t startingSequence)
|
||||
lgrInfo, std::move(*ledgerData->mutable_ledger_header()));
|
||||
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " wrote ledger";
|
||||
std::vector<AccountTransactionsData> accountTxData =
|
||||
FormattedTransactionsData insertTxResult =
|
||||
insertTransactions(lgrInfo, *ledgerData);
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " inserted txns";
|
||||
|
||||
@@ -119,8 +141,12 @@ ReportingETL::loadInitialLedger(uint32_t startingSequence)
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " loaded initial ledger";
|
||||
|
||||
if (!stopping_)
|
||||
backend_->writeAccountTransactions(std::move(accountTxData));
|
||||
|
||||
{
|
||||
backend_->writeAccountTransactions(
|
||||
std::move(insertTxResult.accountTxData));
|
||||
backend_->writeNFTs(std::move(insertTxResult.nfTokensData));
|
||||
backend_->writeNFTTransactions(std::move(insertTxResult.nfTokenTxData));
|
||||
}
|
||||
backend_->finishWrites(startingSequence);
|
||||
|
||||
auto end = std::chrono::system_clock::now();
|
||||
@@ -147,11 +173,9 @@ ReportingETL::publishLedger(ripple::LedgerInfo const& lgrInfo)
|
||||
backend_->cache().update(diff, lgrInfo.seq);
|
||||
backend_->updateRange(lgrInfo.seq);
|
||||
}
|
||||
auto now = std::chrono::duration_cast<std::chrono::seconds>(
|
||||
std::chrono::system_clock::now().time_since_epoch())
|
||||
.count();
|
||||
auto closeTime = lgrInfo.closeTime.time_since_epoch().count();
|
||||
auto age = now - (rippleEpochStart + closeTime);
|
||||
|
||||
setLastClose(lgrInfo.closeTime);
|
||||
auto age = lastCloseAgeSeconds();
|
||||
// if the ledger closed over 10 minutes ago, assume we are still
|
||||
// catching up and don't publish
|
||||
if (age < 600)
|
||||
@@ -513,15 +537,15 @@ ReportingETL::buildNextLedger(org::xrpl::rpc::v1::GetLedgerResponse& rawData)
|
||||
<< __func__ << " : "
|
||||
<< "Inserted/modified/deleted all objects. Number of objects = "
|
||||
<< rawData.ledger_objects().objects_size();
|
||||
std::vector<AccountTransactionsData> accountTxData{
|
||||
insertTransactions(lgrInfo, rawData)};
|
||||
FormattedTransactionsData insertTxResult =
|
||||
insertTransactions(lgrInfo, rawData);
|
||||
BOOST_LOG_TRIVIAL(debug)
|
||||
<< __func__ << " : "
|
||||
<< "Inserted all transactions. Number of transactions = "
|
||||
<< rawData.transactions_list().transactions_size();
|
||||
|
||||
backend_->writeAccountTransactions(std::move(accountTxData));
|
||||
|
||||
backend_->writeAccountTransactions(std::move(insertTxResult.accountTxData));
|
||||
backend_->writeNFTs(std::move(insertTxResult.nfTokensData));
|
||||
backend_->writeNFTTransactions(std::move(insertTxResult.nfTokenTxData));
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " : "
|
||||
<< "wrote account_tx";
|
||||
auto start = std::chrono::system_clock::now();
|
||||
@@ -916,7 +940,7 @@ ReportingETL::loadCache(uint32_t seq)
|
||||
a.insert(std::end(a), std::begin(b), std::end(b));
|
||||
};
|
||||
|
||||
for (size_t i = 0; i < numDiffs_; ++i)
|
||||
for (size_t i = 0; i < numCacheDiffs_; ++i)
|
||||
{
|
||||
append(diff, Backend::synchronousAndRetryOnTimeout([&](auto yield) {
|
||||
return backend_->fetchLedgerDiff(seq - i, yield);
|
||||
@@ -951,55 +975,74 @@ ReportingETL::loadCache(uint32_t seq)
|
||||
<< "Loading cache. num cursors = " << cursors.size() - 1;
|
||||
BOOST_LOG_TRIVIAL(debug) << __func__ << " cursors = " << cursorStr.str();
|
||||
|
||||
std::atomic_uint* numRemaining = new std::atomic_uint{cursors.size() - 1};
|
||||
|
||||
auto startTime = std::chrono::system_clock::now();
|
||||
for (size_t i = 0; i < cursors.size() - 1; ++i)
|
||||
{
|
||||
std::optional<ripple::uint256> start = cursors[i];
|
||||
std::optional<ripple::uint256> end = cursors[i + 1];
|
||||
boost::asio::spawn(
|
||||
ioContext_,
|
||||
[this, seq, start, end, numRemaining, startTime](
|
||||
boost::asio::yield_context yield) {
|
||||
std::optional<ripple::uint256> cursor = start;
|
||||
while (true)
|
||||
{
|
||||
auto res =
|
||||
Backend::retryOnTimeout([this, seq, &cursor, &yield]() {
|
||||
return backend_->fetchLedgerPage(
|
||||
cursor, seq, 256, false, yield);
|
||||
});
|
||||
backend_->cache().update(res.objects, seq, true);
|
||||
if (!res.cursor || (end && *(res.cursor) > *end))
|
||||
break;
|
||||
cacheDownloader_ = std::thread{[this, seq, cursors]() {
|
||||
auto startTime = std::chrono::system_clock::now();
|
||||
auto markers = std::make_shared<std::atomic_int>(0);
|
||||
auto numRemaining =
|
||||
std::make_shared<std::atomic_int>(cursors.size() - 1);
|
||||
for (size_t i = 0; i < cursors.size() - 1; ++i)
|
||||
{
|
||||
std::optional<ripple::uint256> start = cursors[i];
|
||||
std::optional<ripple::uint256> end = cursors[i + 1];
|
||||
markers->wait(numCacheMarkers_);
|
||||
++(*markers);
|
||||
boost::asio::spawn(
|
||||
ioContext_,
|
||||
[this, seq, start, end, numRemaining, startTime, markers](
|
||||
boost::asio::yield_context yield) {
|
||||
std::optional<ripple::uint256> cursor = start;
|
||||
std::string cursorStr = cursor.has_value()
|
||||
? ripple::strHex(cursor.value())
|
||||
: ripple::strHex(Backend::firstKey);
|
||||
BOOST_LOG_TRIVIAL(debug)
|
||||
<< "Loading cache. cache size = "
|
||||
<< backend_->cache().size()
|
||||
<< " - cursor = " << ripple::strHex(res.cursor.value());
|
||||
cursor = std::move(res.cursor);
|
||||
}
|
||||
if (--(*numRemaining) == 0)
|
||||
{
|
||||
auto endTime = std::chrono::system_clock::now();
|
||||
auto duration =
|
||||
std::chrono::duration_cast<std::chrono::seconds>(
|
||||
endTime - startTime);
|
||||
BOOST_LOG_TRIVIAL(info)
|
||||
<< "Finished loading cache. cache size = "
|
||||
<< backend_->cache().size() << ". Took "
|
||||
<< duration.count() << " seconds";
|
||||
backend_->cache().setFull();
|
||||
delete numRemaining;
|
||||
}
|
||||
else
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(info)
|
||||
<< "Finished a cursor. num remaining = "
|
||||
<< *numRemaining;
|
||||
}
|
||||
});
|
||||
}
|
||||
<< "Starting a cursor: " << cursorStr
|
||||
<< " markers = " << *markers;
|
||||
|
||||
while (!stopping_)
|
||||
{
|
||||
auto res = Backend::retryOnTimeout([this,
|
||||
seq,
|
||||
&cursor,
|
||||
&yield]() {
|
||||
return backend_->fetchLedgerPage(
|
||||
cursor, seq, cachePageFetchSize_, false, yield);
|
||||
});
|
||||
backend_->cache().update(res.objects, seq, true);
|
||||
if (!res.cursor || (end && *(res.cursor) > *end))
|
||||
break;
|
||||
BOOST_LOG_TRIVIAL(debug)
|
||||
<< "Loading cache. cache size = "
|
||||
<< backend_->cache().size() << " - cursor = "
|
||||
<< ripple::strHex(res.cursor.value())
|
||||
<< " start = " << cursorStr
|
||||
<< " markers = " << *markers;
|
||||
|
||||
cursor = std::move(res.cursor);
|
||||
}
|
||||
--(*markers);
|
||||
markers->notify_one();
|
||||
if (--(*numRemaining) == 0)
|
||||
{
|
||||
auto endTime = std::chrono::system_clock::now();
|
||||
auto duration =
|
||||
std::chrono::duration_cast<std::chrono::seconds>(
|
||||
endTime - startTime);
|
||||
BOOST_LOG_TRIVIAL(info)
|
||||
<< "Finished loading cache. cache size = "
|
||||
<< backend_->cache().size() << ". Took "
|
||||
<< duration.count() << " seconds";
|
||||
backend_->cache().setFull();
|
||||
}
|
||||
else
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(info)
|
||||
<< "Finished a cursor. num remaining = "
|
||||
<< *numRemaining << " start = " << cursorStr
|
||||
<< " markers = " << *markers;
|
||||
}
|
||||
});
|
||||
}
|
||||
}};
|
||||
// If loading synchronously, poll cache until full
|
||||
while (cacheLoadStyle_ == CacheLoadStyle::SYNC &&
|
||||
!backend_->cache().isFull())
|
||||
@@ -1109,9 +1152,12 @@ ReportingETL::ReportingETL(
|
||||
if (entry == "none" || entry == "no")
|
||||
cacheLoadStyle_ = CacheLoadStyle::NOT_AT_ALL;
|
||||
}
|
||||
if (cache.contains("num_diffs") && cache.at("num_diffs").as_int64())
|
||||
{
|
||||
numDiffs_ = cache.at("num_diffs").as_int64();
|
||||
}
|
||||
if (cache.contains("num_diffs") && cache.at("num_diffs").is_int64())
|
||||
numCacheDiffs_ = cache.at("num_diffs").as_int64();
|
||||
if (cache.contains("num_markers") && cache.at("num_markers").is_int64())
|
||||
numCacheMarkers_ = cache.at("num_markers").as_int64();
|
||||
if (cache.contains("page_fetch_size") &&
|
||||
cache.at("page_fetch_size").is_int64())
|
||||
cachePageFetchSize_ = cache.at("page_fetch_size").as_int64();
|
||||
}
|
||||
}
|
||||
|
||||
@@ -19,7 +19,22 @@
|
||||
|
||||
#include <chrono>
|
||||
|
||||
/**
|
||||
* Helper function for the ReportingETL, implemented in NFTHelpers.cpp, to
|
||||
* pull to-write data out of a transaction that relates to NFTs.
|
||||
*/
|
||||
std::pair<std::vector<NFTTransactionsData>, std::optional<NFTsData>>
|
||||
getNFTData(ripple::TxMeta const& txMeta, ripple::STTx const& sttx);
|
||||
|
||||
struct AccountTransactionsData;
|
||||
struct NFTTransactionsData;
|
||||
struct NFTsData;
|
||||
struct FormattedTransactionsData
|
||||
{
|
||||
std::vector<AccountTransactionsData> accountTxData;
|
||||
std::vector<NFTTransactionsData> nfTokenTxData;
|
||||
std::vector<NFTsData> nfTokensData;
|
||||
};
|
||||
class SubscriptionManager;
|
||||
|
||||
/**
|
||||
@@ -52,7 +67,15 @@ private:
|
||||
|
||||
// number of diffs to use to generate cursors to traverse the ledger in
|
||||
// parallel during initial cache download
|
||||
size_t numDiffs_ = 1;
|
||||
size_t numCacheDiffs_ = 32;
|
||||
// number of markers to use at one time to traverse the ledger in parallel
|
||||
// during initial cache download
|
||||
size_t numCacheMarkers_ = 48;
|
||||
// number of ledger objects to fetch concurrently per marker during cache
|
||||
// download
|
||||
size_t cachePageFetchSize_ = 512;
|
||||
// thread responsible for syncing the cache on startup
|
||||
std::thread cacheDownloader_;
|
||||
|
||||
std::thread worker_;
|
||||
boost::asio::io_context& ioContext_;
|
||||
@@ -139,6 +162,18 @@ private:
|
||||
lastPublish_ = std::chrono::system_clock::now();
|
||||
}
|
||||
|
||||
/// The time that the most recently published ledger was closed.
|
||||
std::chrono::time_point<ripple::NetClock> lastCloseTime_;
|
||||
|
||||
mutable std::shared_mutex closeTimeMtx_;
|
||||
|
||||
void
|
||||
setLastClose(std::chrono::time_point<ripple::NetClock> lastCloseTime)
|
||||
{
|
||||
std::unique_lock lck(closeTimeMtx_);
|
||||
lastCloseTime_ = lastCloseTime;
|
||||
}
|
||||
|
||||
/// Download a ledger with specified sequence in full, via GetLedgerData,
|
||||
/// and write the data to the databases. This takes several minutes or
|
||||
/// longer.
|
||||
@@ -201,14 +236,16 @@ private:
|
||||
std::optional<org::xrpl::rpc::v1::GetLedgerResponse>
|
||||
fetchLedgerDataAndDiff(uint32_t sequence);
|
||||
|
||||
/// Insert all of the extracted transactions into the ledger
|
||||
/// Insert all of the extracted transactions into the ledger, returning
|
||||
/// transactions related to accounts, transactions related to NFTs, and
|
||||
/// NFTs themselves for later processsing.
|
||||
/// @param ledger ledger to insert transactions into
|
||||
/// @param data data extracted from an ETL source
|
||||
/// @return struct that contains the neccessary info to write to the
|
||||
/// transctions and account_transactions tables in Postgres (mostly
|
||||
/// transaction hashes, corresponding nodestore hashes and affected
|
||||
/// account_transactions/account_tx and nft_token_transactions tables
|
||||
/// (mostly transaction hashes, corresponding nodestore hashes and affected
|
||||
/// accounts)
|
||||
std::vector<AccountTransactionsData>
|
||||
FormattedTransactionsData
|
||||
insertTransactions(
|
||||
ripple::LedgerInfo const& ledger,
|
||||
org::xrpl::rpc::v1::GetLedgerResponse& data);
|
||||
@@ -301,6 +338,8 @@ public:
|
||||
|
||||
if (worker_.joinable())
|
||||
worker_.join();
|
||||
if (cacheDownloader_.joinable())
|
||||
cacheDownloader_.join();
|
||||
|
||||
BOOST_LOG_TRIVIAL(debug) << "Joined ReportingETL worker thread";
|
||||
}
|
||||
@@ -334,6 +373,17 @@ public:
|
||||
std::chrono::system_clock::now() - getLastPublish())
|
||||
.count();
|
||||
}
|
||||
|
||||
std::uint32_t
|
||||
lastCloseAgeSeconds() const
|
||||
{
|
||||
std::shared_lock lck(closeTimeMtx_);
|
||||
auto now = std::chrono::duration_cast<std::chrono::seconds>(
|
||||
std::chrono::system_clock::now().time_since_epoch())
|
||||
.count();
|
||||
auto closeTime = lastCloseTime_.time_since_epoch().count();
|
||||
return now - (rippleEpochStart + closeTime);
|
||||
}
|
||||
};
|
||||
|
||||
#endif
|
||||
|
||||
@@ -12,7 +12,7 @@ namespace Build {
|
||||
// and follow the format described at http://semver.org/
|
||||
//------------------------------------------------------------------------------
|
||||
// clang-format off
|
||||
char const* const versionString = "1.0.0"
|
||||
char const* const versionString = "1.0.2"
|
||||
// clang-format on
|
||||
|
||||
#if defined(DEBUG) || defined(SANITIZER)
|
||||
|
||||
@@ -115,8 +115,7 @@ initLogging(boost::json::object const& config)
|
||||
{
|
||||
boost::log::add_console_log(std::cout, keywords::format = format);
|
||||
}
|
||||
if (config.contains("log_to_file") && config.at("log_to_file").as_bool() &&
|
||||
config.contains("log_directory"))
|
||||
if (config.contains("log_directory"))
|
||||
{
|
||||
if (!config.at("log_directory").is_string())
|
||||
throw std::runtime_error("log directory must be a string");
|
||||
|
||||
@@ -55,6 +55,9 @@ doNFTBuyOffers(Context const& context);
|
||||
Result
|
||||
doNFTSellOffers(Context const& context);
|
||||
|
||||
Result
|
||||
doNFTInfo(Context const& context);
|
||||
|
||||
// ledger methods
|
||||
Result
|
||||
doLedger(Context const& context);
|
||||
|
||||
@@ -91,6 +91,38 @@ make_HttpContext(
|
||||
clientIp};
|
||||
}
|
||||
|
||||
constexpr static WarningInfo warningInfos[]{
|
||||
{warnUNKNOWN, "Unknown warning"},
|
||||
{warnRPC_CLIO,
|
||||
"This is a clio server. clio only serves validated data. If you "
|
||||
"want to talk to rippled, include 'ledger_index':'current' in your "
|
||||
"request"},
|
||||
{warnRPC_OUTDATED, "This server may be out of date"},
|
||||
{warnRPC_RATE_LIMIT, "You are about to be rate limited"}};
|
||||
|
||||
WarningInfo const&
|
||||
get_warning_info(warning_code code)
|
||||
{
|
||||
for (WarningInfo const& info : warningInfos)
|
||||
{
|
||||
if (info.code == code)
|
||||
{
|
||||
return info;
|
||||
}
|
||||
}
|
||||
throw(std::out_of_range("Invalid warning_code"));
|
||||
}
|
||||
|
||||
boost::json::object
|
||||
make_warning(warning_code code)
|
||||
{
|
||||
boost::json::object json;
|
||||
WarningInfo const& info(get_warning_info(code));
|
||||
json["id"] = code;
|
||||
json["message"] = static_cast<std::string>(info.message);
|
||||
return json;
|
||||
}
|
||||
|
||||
boost::json::object
|
||||
make_error(Error err)
|
||||
{
|
||||
@@ -191,6 +223,7 @@ static HandlerTable handlerTable{
|
||||
{"ledger", &doLedger, {}},
|
||||
{"ledger_data", &doLedgerData, LimitRange{1, 100, 2048}},
|
||||
{"nft_buy_offers", &doNFTBuyOffers, LimitRange{1, 50, 100}},
|
||||
{"nft_info", &doNFTInfo},
|
||||
{"nft_sell_offers", &doNFTSellOffers, LimitRange{1, 50, 100}},
|
||||
{"ledger_entry", &doLedgerEntry, {}},
|
||||
{"ledger_range", &doLedgerRange, {}},
|
||||
|
||||
@@ -162,6 +162,33 @@ public:
|
||||
}
|
||||
};
|
||||
|
||||
enum warning_code {
|
||||
warnUNKNOWN = -1,
|
||||
warnRPC_CLIO = 2001,
|
||||
warnRPC_OUTDATED = 2002,
|
||||
warnRPC_RATE_LIMIT = 2003
|
||||
};
|
||||
|
||||
struct WarningInfo
|
||||
{
|
||||
constexpr WarningInfo() : code(warnUNKNOWN), message("unknown warning")
|
||||
{
|
||||
}
|
||||
|
||||
constexpr WarningInfo(warning_code code_, char const* message_)
|
||||
: code(code_), message(message_)
|
||||
{
|
||||
}
|
||||
warning_code code;
|
||||
std::string_view const message;
|
||||
};
|
||||
|
||||
WarningInfo const&
|
||||
get_warning_info(warning_code code);
|
||||
|
||||
boost::json::object
|
||||
make_warning(warning_code code);
|
||||
|
||||
boost::json::object
|
||||
make_error(Status const& status);
|
||||
|
||||
|
||||
@@ -569,7 +569,7 @@ ledgerInfoFromRequest(Context const& ctx)
|
||||
|
||||
auto lgrInfo = ctx.backend->fetchLedgerByHash(ledgerHash, ctx.yield);
|
||||
|
||||
if (!lgrInfo)
|
||||
if (!lgrInfo || lgrInfo->seq > ctx.range.maxSequence)
|
||||
return Status{Error::rpcLGR_NOT_FOUND, "ledgerNotFound"};
|
||||
|
||||
return *lgrInfo;
|
||||
@@ -604,7 +604,7 @@ ledgerInfoFromRequest(Context const& ctx)
|
||||
auto lgrInfo =
|
||||
ctx.backend->fetchLedgerBySequence(*ledgerSequence, ctx.yield);
|
||||
|
||||
if (!lgrInfo)
|
||||
if (!lgrInfo || lgrInfo->seq > ctx.range.maxSequence)
|
||||
return Status{Error::rpcLGR_NOT_FOUND, "ledgerNotFound"};
|
||||
|
||||
return *lgrInfo;
|
||||
|
||||
@@ -19,7 +19,7 @@ doAccountTx(Context const& context)
|
||||
bool const binary = getBool(request, JS(binary), false);
|
||||
bool const forward = getBool(request, JS(forward), false);
|
||||
|
||||
std::optional<Backend::AccountTransactionsCursor> cursor;
|
||||
std::optional<Backend::TransactionsCursor> cursor;
|
||||
|
||||
if (request.contains(JS(marker)))
|
||||
{
|
||||
|
||||
@@ -132,7 +132,7 @@ doLedger(Context const& context)
|
||||
for (auto const& obj : diff)
|
||||
{
|
||||
boost::json::object entry;
|
||||
entry[JS(id)] = ripple::strHex(obj.key);
|
||||
entry["object_id"] = ripple::strHex(obj.key);
|
||||
if (binary)
|
||||
entry["object"] = ripple::strHex(obj.blob);
|
||||
else if (obj.blob.size())
|
||||
|
||||
@@ -79,7 +79,7 @@ doLedgerData(Context const& context)
|
||||
|
||||
boost::json::object header;
|
||||
// no marker means this is the first call, so we return header info
|
||||
if (!marker)
|
||||
if (!request.contains(JS(marker)))
|
||||
{
|
||||
if (binary)
|
||||
{
|
||||
@@ -106,9 +106,9 @@ doLedgerData(Context const& context)
|
||||
header[JS(totalCoins)] = ripple::to_string(lgrInfo.drops);
|
||||
header[JS(total_coins)] = ripple::to_string(lgrInfo.drops);
|
||||
header[JS(transaction_hash)] = ripple::strHex(lgrInfo.txHash);
|
||||
|
||||
response[JS(ledger)] = header;
|
||||
}
|
||||
|
||||
response[JS(ledger)] = header;
|
||||
}
|
||||
else
|
||||
{
|
||||
|
||||
146
src/rpc/handlers/NFTInfo.cpp
Normal file
146
src/rpc/handlers/NFTInfo.cpp
Normal file
@@ -0,0 +1,146 @@
|
||||
#include <ripple/app/tx/impl/details/NFTokenUtils.h>
|
||||
#include <ripple/protocol/Indexes.h>
|
||||
#include <boost/json.hpp>
|
||||
|
||||
#include <backend/BackendInterface.h>
|
||||
#include <rpc/RPCHelpers.h>
|
||||
|
||||
// {
|
||||
// nft_id: <ident>
|
||||
// ledger_hash: <ledger>
|
||||
// ledger_index: <ledger_index>
|
||||
// }
|
||||
|
||||
namespace RPC {
|
||||
|
||||
std::variant<std::monostate, std::string, Status>
|
||||
getURI(Backend::NFT const& dbResponse, Context const& context)
|
||||
{
|
||||
// Fetch URI from ledger
|
||||
// The correct page will be > bookmark and <= last. We need to calculate
|
||||
// the first possible page however, since bookmark is not guaranteed to
|
||||
// exist.
|
||||
auto const bookmark = ripple::keylet::nftpage(
|
||||
ripple::keylet::nftpage_min(dbResponse.owner), dbResponse.tokenID);
|
||||
auto const last = ripple::keylet::nftpage_max(dbResponse.owner);
|
||||
|
||||
ripple::uint256 nextKey = last.key;
|
||||
std::optional<ripple::STLedgerEntry> sle;
|
||||
|
||||
// when this loop terminates, `sle` will contain the correct page for
|
||||
// this NFT.
|
||||
//
|
||||
// 1) We start at the last NFTokenPage, which is guaranteed to exist,
|
||||
// grab the object from the DB and deserialize it.
|
||||
//
|
||||
// 2) If that NFTokenPage has a PreviousPageMin value and the
|
||||
// PreviousPageMin value is > bookmark, restart loop. Otherwise
|
||||
// terminate and use the `sle` from this iteration.
|
||||
do
|
||||
{
|
||||
auto const blob = context.backend->fetchLedgerObject(
|
||||
ripple::Keylet(ripple::ltNFTOKEN_PAGE, nextKey).key,
|
||||
dbResponse.ledgerSequence,
|
||||
context.yield);
|
||||
|
||||
if (!blob || blob->size() == 0)
|
||||
return Status{
|
||||
Error::rpcINTERNAL, "Cannot find NFTokenPage for this NFT"};
|
||||
|
||||
sle = ripple::STLedgerEntry(
|
||||
ripple::SerialIter{blob->data(), blob->size()}, nextKey);
|
||||
|
||||
if (sle->isFieldPresent(ripple::sfPreviousPageMin))
|
||||
nextKey = sle->getFieldH256(ripple::sfPreviousPageMin);
|
||||
|
||||
} while (sle && sle->key() != nextKey && nextKey > bookmark.key);
|
||||
|
||||
if (!sle)
|
||||
return Status{
|
||||
Error::rpcINTERNAL, "Cannot find NFTokenPage for this NFT"};
|
||||
|
||||
auto const nfts = sle->getFieldArray(ripple::sfNFTokens);
|
||||
auto const nft = std::find_if(
|
||||
nfts.begin(),
|
||||
nfts.end(),
|
||||
[&dbResponse](ripple::STObject const& candidate) {
|
||||
return candidate.getFieldH256(ripple::sfNFTokenID) ==
|
||||
dbResponse.tokenID;
|
||||
});
|
||||
|
||||
if (nft == nfts.end())
|
||||
return Status{
|
||||
Error::rpcINTERNAL, "Cannot find NFTokenPage for this NFT"};
|
||||
|
||||
ripple::Blob const uriField = nft->getFieldVL(ripple::sfURI);
|
||||
|
||||
// NOTE this cannot use a ternary or value_or because then the
|
||||
// expression's type is unclear. We want to explicitly set the `uri`
|
||||
// field to null when not present to avoid any confusion.
|
||||
if (std::string const uri = std::string(uriField.begin(), uriField.end());
|
||||
uri.size() > 0)
|
||||
return uri;
|
||||
return std::monostate{};
|
||||
}
|
||||
|
||||
Result
|
||||
doNFTInfo(Context const& context)
|
||||
{
|
||||
auto request = context.params;
|
||||
boost::json::object response = {};
|
||||
|
||||
if (!request.contains("nft_id"))
|
||||
return Status{Error::rpcINVALID_PARAMS, "Missing nft_id"};
|
||||
|
||||
auto const& jsonTokenID = request.at("nft_id");
|
||||
if (!jsonTokenID.is_string())
|
||||
return Status{Error::rpcINVALID_PARAMS, "nft_id is not a string"};
|
||||
|
||||
ripple::uint256 tokenID;
|
||||
if (!tokenID.parseHex(jsonTokenID.as_string().c_str()))
|
||||
return Status{Error::rpcINVALID_PARAMS, "Malformed nft_id"};
|
||||
|
||||
// We only need to fetch the ledger header because the ledger hash is
|
||||
// supposed to be included in the response. The ledger sequence is specified
|
||||
// in the request
|
||||
auto v = ledgerInfoFromRequest(context);
|
||||
if (auto status = std::get_if<Status>(&v))
|
||||
return *status;
|
||||
ripple::LedgerInfo lgrInfo = std::get<ripple::LedgerInfo>(v);
|
||||
|
||||
std::optional<Backend::NFT> dbResponse =
|
||||
context.backend->fetchNFT(tokenID, lgrInfo.seq, context.yield);
|
||||
if (!dbResponse)
|
||||
return Status{Error::rpcOBJECT_NOT_FOUND, "NFT not found"};
|
||||
|
||||
response["nft_id"] = ripple::strHex(dbResponse->tokenID);
|
||||
response["ledger_index"] = dbResponse->ledgerSequence;
|
||||
response["owner"] = ripple::toBase58(dbResponse->owner);
|
||||
response["is_burned"] = dbResponse->isBurned;
|
||||
|
||||
response["flags"] = ripple::nft::getFlags(dbResponse->tokenID);
|
||||
response["transfer_fee"] = ripple::nft::getTransferFee(dbResponse->tokenID);
|
||||
response["issuer"] =
|
||||
ripple::toBase58(ripple::nft::getIssuer(dbResponse->tokenID));
|
||||
response["nft_taxon"] =
|
||||
ripple::nft::toUInt32(ripple::nft::getTaxon(dbResponse->tokenID));
|
||||
response["nft_sequence"] = ripple::nft::getSerial(dbResponse->tokenID);
|
||||
|
||||
if (!dbResponse->isBurned)
|
||||
{
|
||||
auto const maybeURI = getURI(*dbResponse, context);
|
||||
// An error occurred
|
||||
if (Status const* status = std::get_if<Status>(&maybeURI))
|
||||
return *status;
|
||||
// A URI was found
|
||||
if (std::string const* uri = std::get_if<std::string>(&maybeURI))
|
||||
response["uri"] = *uri;
|
||||
// A URI was not found, explicitly set to null
|
||||
else
|
||||
response["uri"] = nullptr;
|
||||
}
|
||||
|
||||
return response;
|
||||
}
|
||||
|
||||
} // namespace RPC
|
||||
@@ -43,10 +43,15 @@ doServerInfo(Context const& context)
|
||||
info[JS(complete_ledgers)] = std::to_string(range->minSequence) + "-" +
|
||||
std::to_string(range->maxSequence);
|
||||
|
||||
info[JS(counters)] = boost::json::object{};
|
||||
info[JS(counters)].as_object()[JS(rpc)] = context.counters.report();
|
||||
info[JS(counters)].as_object()["subscriptions"] =
|
||||
context.subscriptions->report();
|
||||
bool admin = context.clientIp == "127.0.0.1";
|
||||
|
||||
if (admin)
|
||||
{
|
||||
info[JS(counters)] = boost::json::object{};
|
||||
info[JS(counters)].as_object()[JS(rpc)] = context.counters.report();
|
||||
info[JS(counters)].as_object()["subscriptions"] =
|
||||
context.subscriptions->report();
|
||||
}
|
||||
|
||||
auto serverInfoRippled = context.balancer->forwardToRippled(
|
||||
{{"command", "server_info"}}, context.clientIp, context.yield);
|
||||
@@ -78,15 +83,18 @@ doServerInfo(Context const& context)
|
||||
validated[JS(reserve_base_xrp)] = fees->reserve.decimalXRP();
|
||||
validated[JS(reserve_inc_xrp)] = fees->increment.decimalXRP();
|
||||
|
||||
response["cache"] = boost::json::object{};
|
||||
auto& cache = response["cache"].as_object();
|
||||
info["cache"] = boost::json::object{};
|
||||
auto& cache = info["cache"].as_object();
|
||||
|
||||
cache["size"] = context.backend->cache().size();
|
||||
cache["is_full"] = context.backend->cache().isFull();
|
||||
cache["latest_ledger_seq"] =
|
||||
context.backend->cache().latestLedgerSequence();
|
||||
|
||||
response["etl"] = context.etl->getInfo();
|
||||
if (admin)
|
||||
{
|
||||
info["etl"] = context.etl->getInfo();
|
||||
}
|
||||
|
||||
return response;
|
||||
}
|
||||
|
||||
@@ -15,6 +15,7 @@ class DOSGuard
|
||||
std::uint32_t const maxFetches_;
|
||||
std::uint32_t const sweepInterval_;
|
||||
|
||||
// Load config setting for DOSGuard
|
||||
std::optional<boost::json::object>
|
||||
getConfig(boost::json::object const& config) const
|
||||
{
|
||||
|
||||
@@ -242,12 +242,16 @@ public:
|
||||
},
|
||||
dosGuard_.isWhiteListed(*ip)))
|
||||
{
|
||||
// Non-whitelist connection rejected due to full connection queue
|
||||
http::response<http::string_body> res{
|
||||
http::status::ok, req_.version()};
|
||||
res.set(http::field::server, "clio-server-v0.0.0");
|
||||
res.set(
|
||||
http::field::server,
|
||||
"clio-server-" + Build::getClioVersionString());
|
||||
res.set(http::field::content_type, "application/json");
|
||||
res.keep_alive(req_.keep_alive());
|
||||
res.body() = "Server overloaded";
|
||||
res.body() = boost::json::serialize(
|
||||
RPC::make_error(RPC::Error::rpcTOO_BUSY));
|
||||
res.prepare_payload();
|
||||
lambda_(std::move(res));
|
||||
}
|
||||
@@ -304,7 +308,9 @@ handle_request(
|
||||
std::string content_type,
|
||||
std::string message) {
|
||||
http::response<http::string_body> res{status, req.version()};
|
||||
res.set(http::field::server, "xrpl-reporting-server-v0.0.0");
|
||||
res.set(
|
||||
http::field::server,
|
||||
"clio-server-" + Build::getClioVersionString());
|
||||
res.set(http::field::content_type, content_type);
|
||||
res.keep_alive(req.keep_alive());
|
||||
res.body() = std::string(message);
|
||||
@@ -324,9 +330,9 @@ handle_request(
|
||||
|
||||
if (!dosGuard.isOk(ip))
|
||||
return send(httpResponse(
|
||||
http::status::ok,
|
||||
"application/json",
|
||||
boost::json::serialize(RPC::make_error(RPC::Error::rpcSLOW_DOWN))));
|
||||
http::status::service_unavailable,
|
||||
"text/plain",
|
||||
"Server is overloaded"));
|
||||
|
||||
try
|
||||
{
|
||||
@@ -350,13 +356,6 @@ handle_request(
|
||||
RPC::make_error(RPC::Error::rpcBAD_SYNTAX))));
|
||||
}
|
||||
|
||||
if (!dosGuard.isOk(ip))
|
||||
return send(httpResponse(
|
||||
http::status::ok,
|
||||
"application/json",
|
||||
boost::json::serialize(
|
||||
RPC::make_error(RPC::Error::rpcSLOW_DOWN))));
|
||||
|
||||
auto range = backend->fetchLedgerRange();
|
||||
if (!range)
|
||||
return send(httpResponse(
|
||||
@@ -418,18 +417,16 @@ handle_request(
|
||||
}
|
||||
|
||||
boost::json::array warnings;
|
||||
warnings.emplace_back(
|
||||
"This is a clio server. clio only serves validated data. If you "
|
||||
"want to talk to rippled, include 'ledger_index':'current' in your "
|
||||
"request");
|
||||
auto lastPublishAge = context->etl->lastPublishAgeSeconds();
|
||||
if (lastPublishAge >= 60)
|
||||
warnings.emplace_back("This server may be out of date");
|
||||
result["warnings"] = warnings;
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_CLIO));
|
||||
auto lastCloseAge = context->etl->lastCloseAgeSeconds();
|
||||
if (lastCloseAge >= 60)
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_OUTDATED));
|
||||
response["warnings"] = warnings;
|
||||
responseStr = boost::json::serialize(response);
|
||||
if (!dosGuard.add(ip, responseStr.size()))
|
||||
{
|
||||
warnings.emplace_back("Too many requests");
|
||||
response["warning"] = "load";
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_RATE_LIMIT));
|
||||
response["warnings"] = warnings;
|
||||
// reserialize when we need to include this warning
|
||||
responseStr = boost::json::serialize(response);
|
||||
|
||||
@@ -321,8 +321,8 @@ make_HttpServer(
|
||||
static_cast<unsigned short>(serverConfig.at("port").as_int64());
|
||||
|
||||
uint32_t numThreads = std::thread::hardware_concurrency();
|
||||
if (serverConfig.contains("workers"))
|
||||
numThreads = serverConfig.at("workers").as_int64();
|
||||
if (config.contains("workers"))
|
||||
numThreads = config.at("workers").as_int64();
|
||||
uint32_t maxQueueSize = 0; // no max
|
||||
if (serverConfig.contains("max_queue_size"))
|
||||
maxQueueSize = serverConfig.at("max_queue_size").as_int64();
|
||||
|
||||
@@ -245,40 +245,24 @@ public:
|
||||
}
|
||||
|
||||
void
|
||||
handle_request(std::string const&& msg, boost::asio::yield_context& yc)
|
||||
handle_request(
|
||||
boost::json::object const&& request,
|
||||
boost::json::value const& id,
|
||||
boost::asio::yield_context& yield)
|
||||
{
|
||||
auto ip = derived().ip();
|
||||
if (!ip)
|
||||
return;
|
||||
|
||||
boost::json::object response = {};
|
||||
auto sendError = [this](auto error, boost::json::value id) {
|
||||
auto sendError = [this, &request, id](auto error) {
|
||||
auto e = RPC::make_error(error);
|
||||
|
||||
if (!id.is_null())
|
||||
e["id"] = id;
|
||||
|
||||
e["request"] = request;
|
||||
send(boost::json::serialize(e));
|
||||
};
|
||||
|
||||
boost::json::value raw = [](std::string const&& msg) {
|
||||
try
|
||||
{
|
||||
return boost::json::parse(msg);
|
||||
}
|
||||
catch (std::exception&)
|
||||
{
|
||||
return boost::json::value{nullptr};
|
||||
}
|
||||
}(std::move(msg));
|
||||
|
||||
if (!raw.is_object())
|
||||
return sendError(RPC::Error::rpcINVALID_PARAMS, nullptr);
|
||||
|
||||
boost::json::object request = raw.as_object();
|
||||
|
||||
auto id = request.contains("id") ? request.at("id") : nullptr;
|
||||
|
||||
try
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(debug) << " received request : " << request;
|
||||
@@ -286,10 +270,10 @@ public:
|
||||
{
|
||||
auto range = backend_->fetchLedgerRange();
|
||||
if (!range)
|
||||
return sendError(RPC::Error::rpcNOT_READY, id);
|
||||
return sendError(RPC::Error::rpcNOT_READY);
|
||||
|
||||
std::optional<RPC::Context> context = RPC::make_WsContext(
|
||||
yc,
|
||||
yield,
|
||||
request,
|
||||
backend_,
|
||||
subscriptions_.lock(),
|
||||
@@ -301,7 +285,7 @@ public:
|
||||
*ip);
|
||||
|
||||
if (!context)
|
||||
return sendError(RPC::Error::rpcBAD_SYNTAX, id);
|
||||
return sendError(RPC::Error::rpcBAD_SYNTAX);
|
||||
|
||||
response = getDefaultWsResponse(id);
|
||||
|
||||
@@ -334,7 +318,7 @@ public:
|
||||
catch (Backend::DatabaseTimeout const& t)
|
||||
{
|
||||
BOOST_LOG_TRIVIAL(error) << __func__ << " Database timeout";
|
||||
return sendError(RPC::Error::rpcNOT_READY, id);
|
||||
return sendError(RPC::Error::rpcNOT_READY);
|
||||
}
|
||||
}
|
||||
catch (std::exception const& e)
|
||||
@@ -342,24 +326,22 @@ public:
|
||||
BOOST_LOG_TRIVIAL(error)
|
||||
<< __func__ << " caught exception : " << e.what();
|
||||
|
||||
return sendError(RPC::Error::rpcINTERNAL, id);
|
||||
return sendError(RPC::Error::rpcINTERNAL);
|
||||
}
|
||||
|
||||
boost::json::array warnings;
|
||||
warnings.emplace_back(
|
||||
"This is a clio server. clio only serves validated data. If you "
|
||||
"want to talk to rippled, include 'ledger_index':'current' in your "
|
||||
"request");
|
||||
|
||||
auto lastPublishAge = etl_->lastPublishAgeSeconds();
|
||||
if (lastPublishAge >= 60)
|
||||
warnings.emplace_back("This server may be out of date");
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_CLIO));
|
||||
|
||||
auto lastCloseAge = etl_->lastCloseAgeSeconds();
|
||||
if (lastCloseAge >= 60)
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_OUTDATED));
|
||||
response["warnings"] = warnings;
|
||||
std::string responseStr = boost::json::serialize(response);
|
||||
if (!dosGuard_.add(*ip, responseStr.size()))
|
||||
{
|
||||
warnings.emplace_back("Too many requests");
|
||||
response["warning"] = "load";
|
||||
warnings.emplace_back(RPC::make_warning(RPC::warnRPC_RATE_LIMIT));
|
||||
response["warnings"] = warnings;
|
||||
// reserialize if we need to include this warning
|
||||
responseStr = boost::json::serialize(response);
|
||||
@@ -384,33 +366,59 @@ public:
|
||||
|
||||
BOOST_LOG_TRIVIAL(debug)
|
||||
<< __func__ << " received request from ip = " << *ip;
|
||||
auto sendError = [&](auto&& msg) {
|
||||
boost::json::object response;
|
||||
response["error"] = std::move(msg);
|
||||
std::string responseStr = boost::json::serialize(response);
|
||||
|
||||
auto sendError = [this, ip](
|
||||
auto error,
|
||||
boost::json::value const& id,
|
||||
boost::json::object const& request) {
|
||||
auto e = RPC::make_error(error);
|
||||
|
||||
if (!id.is_null())
|
||||
e["id"] = id;
|
||||
e["request"] = request;
|
||||
|
||||
auto responseStr = boost::json::serialize(e);
|
||||
BOOST_LOG_TRIVIAL(trace) << __func__ << " : " << responseStr;
|
||||
|
||||
dosGuard_.add(*ip, responseStr.size());
|
||||
send(std::move(responseStr));
|
||||
};
|
||||
|
||||
boost::json::value raw = [](std::string const&& msg) {
|
||||
try
|
||||
{
|
||||
return boost::json::parse(msg);
|
||||
}
|
||||
catch (std::exception&)
|
||||
{
|
||||
return boost::json::value{nullptr};
|
||||
}
|
||||
}(std::move(msg));
|
||||
|
||||
boost::json::object request;
|
||||
if (!raw.is_object())
|
||||
return sendError(RPC::Error::rpcINVALID_PARAMS, nullptr, request);
|
||||
request = raw.as_object();
|
||||
|
||||
auto id = request.contains("id") ? request.at("id") : nullptr;
|
||||
|
||||
if (!dosGuard_.isOk(*ip))
|
||||
{
|
||||
sendError("Too many requests. Slow down");
|
||||
sendError(RPC::Error::rpcSLOW_DOWN, id, request);
|
||||
}
|
||||
else
|
||||
{
|
||||
if (!queue_.postCoro(
|
||||
[m = std::move(msg), shared_this = shared_from_this()](
|
||||
boost::asio::yield_context yield) {
|
||||
shared_this->handle_request(std::move(m), yield);
|
||||
[shared_this = shared_from_this(),
|
||||
r = std::move(request),
|
||||
id](boost::asio::yield_context yield) {
|
||||
shared_this->handle_request(std::move(r), id, yield);
|
||||
},
|
||||
dosGuard_.isWhiteListed(*ip)))
|
||||
sendError("Server overloaded");
|
||||
sendError(RPC::Error::rpcTOO_BUSY, id, request);
|
||||
}
|
||||
|
||||
do_read();
|
||||
}
|
||||
};
|
||||
|
||||
#endif // RIPPLE_REPORTING_WS_BASE_SESSION_H
|
||||
#endif // RIPPLE_REPORTING_WS_BASE_SESSION_H
|
||||
31
test.py
31
test.py
@@ -475,14 +475,13 @@ async def ledger_data(ip, port, ledger, limit, binary, cursor):
|
||||
except websockets.exceptions.connectionclosederror as e:
|
||||
print(e)
|
||||
|
||||
def writeLedgerData(data,filename):
|
||||
print(len(data[0]))
|
||||
def writeLedgerData(state,filename):
|
||||
print(len(state))
|
||||
|
||||
with open(filename,'w') as f:
|
||||
data[0].sort()
|
||||
data[1].sort()
|
||||
for k,v in zip(data[0],data[1]):
|
||||
for k,v in state.items():
|
||||
f.write(k)
|
||||
f.write('\n')
|
||||
f.write(':')
|
||||
f.write(v)
|
||||
f.write('\n')
|
||||
|
||||
@@ -490,15 +489,14 @@ def writeLedgerData(data,filename):
|
||||
async def ledger_data_full(ip, port, ledger, binary, limit, typ=None, count=-1, marker = None):
|
||||
address = 'ws://' + str(ip) + ':' + str(port)
|
||||
try:
|
||||
blobs = []
|
||||
keys = []
|
||||
state = {}
|
||||
async with websockets.connect(address,max_size=1000000000) as ws:
|
||||
if int(limit) < 2048:
|
||||
limit = 2048
|
||||
while True:
|
||||
res = {}
|
||||
if marker is None:
|
||||
await ws.send(json.dumps({"command":"ledger_data","ledger_index":int(ledger),"binary":binary, "limit":int(limit)}))
|
||||
await ws.send(json.dumps({"command":"ledger_data","ledger_index":int(ledger),"binary":binary, "limit":int(limit),"out_of_order":True}))
|
||||
res = json.loads(await ws.recv())
|
||||
|
||||
else:
|
||||
@@ -520,16 +518,15 @@ async def ledger_data_full(ip, port, ledger, binary, limit, typ=None, count=-1,
|
||||
if binary:
|
||||
if typ is None or x["data"][2:6] == typ:
|
||||
#print(json.dumps(x))
|
||||
keys.append(x["index"])
|
||||
state[x["index"]] = x["data"]
|
||||
else:
|
||||
if typ is None or x["LedgerEntryType"] == typ:
|
||||
blobs.append(x)
|
||||
keys.append(x["index"])
|
||||
if count != -1 and len(keys) > count:
|
||||
state[x["index"]] = x
|
||||
if count != -1 and len(state) > count:
|
||||
print("stopping early")
|
||||
print(len(keys))
|
||||
print(len(state))
|
||||
print("done")
|
||||
return (keys,blobs)
|
||||
return state
|
||||
if "cursor" in res:
|
||||
marker = res["cursor"]
|
||||
print(marker)
|
||||
@@ -538,7 +535,7 @@ async def ledger_data_full(ip, port, ledger, binary, limit, typ=None, count=-1,
|
||||
print(marker)
|
||||
else:
|
||||
print("done")
|
||||
return (keys, blobs)
|
||||
return state
|
||||
|
||||
|
||||
except websockets.exceptions.connectionclosederror as e:
|
||||
@@ -1263,7 +1260,7 @@ def run(args):
|
||||
|
||||
res = asyncio.get_event_loop().run_until_complete(
|
||||
ledger_data_full(args.ip, args.port, args.ledger, bool(args.binary), args.limit,args.type, int(args.count), args.marker))
|
||||
print(len(res[0]))
|
||||
print(len(res))
|
||||
if args.verify:
|
||||
writeLedgerData(res,args.filename)
|
||||
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
#include <algorithm>
|
||||
#include <backend/DBHelpers.h>
|
||||
#include <etl/ReportingETL.h>
|
||||
#include <gtest/gtest.h>
|
||||
#include <rpc/RPCHelpers.h>
|
||||
|
||||
@@ -296,6 +297,122 @@ TEST(BackendTest, Basic)
|
||||
"E0311EB450B6177F969B94DBDDA83E99B7A0576ACD9079573876F16C0C"
|
||||
"004F06";
|
||||
|
||||
// An NFTokenMint tx
|
||||
std::string nftTxnHex =
|
||||
"1200192200000008240011CC9B201B001F71D6202A0000000168400000"
|
||||
"000000000C7321ED475D1452031E8F9641AF1631519A58F7B8681E172E"
|
||||
"4838AA0E59408ADA1727DD74406960041F34F10E0CBB39444B4D4E577F"
|
||||
"C0B7E8D843D091C2917E96E7EE0E08B30C91413EC551A2B8A1D405E8BA"
|
||||
"34FE185D8B10C53B40928611F2DE3B746F0303751868747470733A2F2F"
|
||||
"677265677765697362726F642E636F6D81146203F49C21D5D6E022CB16"
|
||||
"DE3538F248662FC73C";
|
||||
|
||||
std::string nftTxnMeta =
|
||||
"201C00000001F8E511005025001F71B3556ED9C9459001E4F4A9121F4E"
|
||||
"07AB6D14898A5BBEF13D85C25D743540DB59F3CF566203F49C21D5D6E0"
|
||||
"22CB16DE3538F248662FC73CFFFFFFFFFFFFFFFFFFFFFFFFE6FAEC5A00"
|
||||
"0800006203F49C21D5D6E022CB16DE3538F248662FC73C8962EFA00000"
|
||||
"0006751868747470733A2F2F677265677765697362726F642E636F6DE1"
|
||||
"EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73C93E8B1"
|
||||
"C200000028751868747470733A2F2F677265677765697362726F642E63"
|
||||
"6F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73C"
|
||||
"9808B6B90000001D751868747470733A2F2F677265677765697362726F"
|
||||
"642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F24866"
|
||||
"2FC73C9C28BBAC00000012751868747470733A2F2F6772656777656973"
|
||||
"62726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538"
|
||||
"F248662FC73CA048C0A300000007751868747470733A2F2F6772656777"
|
||||
"65697362726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16"
|
||||
"DE3538F248662FC73CAACE82C500000029751868747470733A2F2F6772"
|
||||
"65677765697362726F642E636F6DE1EC5A000800006203F49C21D5D6E0"
|
||||
"22CB16DE3538F248662FC73CAEEE87B80000001E751868747470733A2F"
|
||||
"2F677265677765697362726F642E636F6DE1EC5A000800006203F49C21"
|
||||
"D5D6E022CB16DE3538F248662FC73CB30E8CAF00000013751868747470"
|
||||
"733A2F2F677265677765697362726F642E636F6DE1EC5A000800006203"
|
||||
"F49C21D5D6E022CB16DE3538F248662FC73CB72E91A200000008751868"
|
||||
"747470733A2F2F677265677765697362726F642E636F6DE1EC5A000800"
|
||||
"006203F49C21D5D6E022CB16DE3538F248662FC73CC1B453C40000002A"
|
||||
"751868747470733A2F2F677265677765697362726F642E636F6DE1EC5A"
|
||||
"000800006203F49C21D5D6E022CB16DE3538F248662FC73CC5D458BB00"
|
||||
"00001F751868747470733A2F2F677265677765697362726F642E636F6D"
|
||||
"E1EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73CC9F4"
|
||||
"5DAE00000014751868747470733A2F2F677265677765697362726F642E"
|
||||
"636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC7"
|
||||
"3CCE1462A500000009751868747470733A2F2F67726567776569736272"
|
||||
"6F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248"
|
||||
"662FC73CD89A24C70000002B751868747470733A2F2F67726567776569"
|
||||
"7362726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE35"
|
||||
"38F248662FC73CDCBA29BA00000020751868747470733A2F2F67726567"
|
||||
"7765697362726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB"
|
||||
"16DE3538F248662FC73CE0DA2EB100000015751868747470733A2F2F67"
|
||||
"7265677765697362726F642E636F6DE1EC5A000800006203F49C21D5D6"
|
||||
"E022CB16DE3538F248662FC73CE4FA33A40000000A751868747470733A"
|
||||
"2F2F677265677765697362726F642E636F6DE1EC5A000800006203F49C"
|
||||
"21D5D6E022CB16DE3538F248662FC73CF39FFABD000000217518687474"
|
||||
"70733A2F2F677265677765697362726F642E636F6DE1EC5A0008000062"
|
||||
"03F49C21D5D6E022CB16DE3538F248662FC73CF7BFFFB0000000167518"
|
||||
"68747470733A2F2F677265677765697362726F642E636F6DE1EC5A0008"
|
||||
"00006203F49C21D5D6E022CB16DE3538F248662FC73CFBE004A7000000"
|
||||
"0B751868747470733A2F2F677265677765697362726F642E636F6DE1F1"
|
||||
"E1E72200000000501A6203F49C21D5D6E022CB16DE3538F248662FC73C"
|
||||
"662FC73C8962EFA000000006FAEC5A000800006203F49C21D5D6E022CB"
|
||||
"16DE3538F248662FC73C8962EFA000000006751868747470733A2F2F67"
|
||||
"7265677765697362726F642E636F6DE1EC5A000800006203F49C21D5D6"
|
||||
"E022CB16DE3538F248662FC73C93E8B1C200000028751868747470733A"
|
||||
"2F2F677265677765697362726F642E636F6DE1EC5A000800006203F49C"
|
||||
"21D5D6E022CB16DE3538F248662FC73C9808B6B90000001D7518687474"
|
||||
"70733A2F2F677265677765697362726F642E636F6DE1EC5A0008000062"
|
||||
"03F49C21D5D6E022CB16DE3538F248662FC73C9C28BBAC000000127518"
|
||||
"68747470733A2F2F677265677765697362726F642E636F6DE1EC5A0008"
|
||||
"00006203F49C21D5D6E022CB16DE3538F248662FC73CA048C0A3000000"
|
||||
"07751868747470733A2F2F677265677765697362726F642E636F6DE1EC"
|
||||
"5A000800006203F49C21D5D6E022CB16DE3538F248662FC73CAACE82C5"
|
||||
"00000029751868747470733A2F2F677265677765697362726F642E636F"
|
||||
"6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73CAE"
|
||||
"EE87B80000001E751868747470733A2F2F677265677765697362726F64"
|
||||
"2E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248662F"
|
||||
"C73CB30E8CAF00000013751868747470733A2F2F677265677765697362"
|
||||
"726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F2"
|
||||
"48662FC73CB72E91A200000008751868747470733A2F2F677265677765"
|
||||
"697362726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE"
|
||||
"3538F248662FC73CC1B453C40000002A751868747470733A2F2F677265"
|
||||
"677765697362726F642E636F6DE1EC5A000800006203F49C21D5D6E022"
|
||||
"CB16DE3538F248662FC73CC5D458BB0000001F751868747470733A2F2F"
|
||||
"677265677765697362726F642E636F6DE1EC5A000800006203F49C21D5"
|
||||
"D6E022CB16DE3538F248662FC73CC9F45DAE0000001475186874747073"
|
||||
"3A2F2F677265677765697362726F642E636F6DE1EC5A000800006203F4"
|
||||
"9C21D5D6E022CB16DE3538F248662FC73CCE1462A50000000975186874"
|
||||
"7470733A2F2F677265677765697362726F642E636F6DE1EC5A00080000"
|
||||
"6203F49C21D5D6E022CB16DE3538F248662FC73CD89A24C70000002B75"
|
||||
"1868747470733A2F2F677265677765697362726F642E636F6DE1EC5A00"
|
||||
"0800006203F49C21D5D6E022CB16DE3538F248662FC73CDCBA29BA0000"
|
||||
"0020751868747470733A2F2F677265677765697362726F642E636F6DE1"
|
||||
"EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73CE0DA2E"
|
||||
"B100000015751868747470733A2F2F677265677765697362726F642E63"
|
||||
"6F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F248662FC73C"
|
||||
"E4FA33A40000000A751868747470733A2F2F677265677765697362726F"
|
||||
"642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538F24866"
|
||||
"2FC73CEF7FF5C60000002C751868747470733A2F2F6772656777656973"
|
||||
"62726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16DE3538"
|
||||
"F248662FC73CF39FFABD00000021751868747470733A2F2F6772656777"
|
||||
"65697362726F642E636F6DE1EC5A000800006203F49C21D5D6E022CB16"
|
||||
"DE3538F248662FC73CF7BFFFB000000016751868747470733A2F2F6772"
|
||||
"65677765697362726F642E636F6DE1EC5A000800006203F49C21D5D6E0"
|
||||
"22CB16DE3538F248662FC73CFBE004A70000000B751868747470733A2F"
|
||||
"2F677265677765697362726F642E636F6DE1F1E1E1E511006125001F71"
|
||||
"B3556ED9C9459001E4F4A9121F4E07AB6D14898A5BBEF13D85C25D7435"
|
||||
"40DB59F3CF56BE121B82D5812149D633F605EB07265A80B762A365CE94"
|
||||
"883089FEEE4B955701E6240011CC9B202B0000002C6240000002540BE3"
|
||||
"ECE1E72200000000240011CC9C2D0000000A202B0000002D202C000000"
|
||||
"066240000002540BE3E081146203F49C21D5D6E022CB16DE3538F24866"
|
||||
"2FC73CE1E1F1031000";
|
||||
std::string nftTxnHashHex =
|
||||
"6C7F69A6D25A13AC4A2E9145999F45D4674F939900017A96885FDC2757"
|
||||
"E9284E";
|
||||
ripple::uint256 nftID;
|
||||
EXPECT_TRUE(
|
||||
nftID.parseHex("000800006203F49C21D5D6E022CB16DE3538F248662"
|
||||
"FC73CEF7FF5C60000002C"));
|
||||
|
||||
std::string metaBlob = hexStringToBinaryString(metaHex);
|
||||
std::string txnBlob = hexStringToBinaryString(txnHex);
|
||||
std::string hashBlob = hexStringToBinaryString(hashHex);
|
||||
@@ -304,6 +421,10 @@ TEST(BackendTest, Basic)
|
||||
hexStringToBinaryString(accountIndexHex);
|
||||
std::vector<ripple::AccountID> affectedAccounts;
|
||||
|
||||
std::string nftTxnBlob = hexStringToBinaryString(nftTxnHex);
|
||||
std::string nftTxnMetaBlob =
|
||||
hexStringToBinaryString(nftTxnMeta);
|
||||
|
||||
{
|
||||
backend->startWrites();
|
||||
lgrInfoNext.seq = lgrInfoNext.seq + 1;
|
||||
@@ -322,9 +443,29 @@ TEST(BackendTest, Basic)
|
||||
{
|
||||
affectedAccounts.push_back(a);
|
||||
}
|
||||
|
||||
std::vector<AccountTransactionsData> accountTxData;
|
||||
accountTxData.emplace_back(txMeta, hash256, journal);
|
||||
|
||||
ripple::uint256 nftHash256;
|
||||
EXPECT_TRUE(nftHash256.parseHex(nftTxnHashHex));
|
||||
ripple::TxMeta nftTxMeta{
|
||||
nftHash256, lgrInfoNext.seq, nftTxnMetaBlob};
|
||||
ripple::SerialIter it{nftTxnBlob.data(), nftTxnBlob.size()};
|
||||
ripple::STTx sttx{it};
|
||||
auto const [parsedNFTTxsRef, parsedNFT] =
|
||||
getNFTData(nftTxMeta, sttx);
|
||||
// need to copy the nft txns so we can std::move later
|
||||
std::vector<NFTTransactionsData> parsedNFTTxs;
|
||||
parsedNFTTxs.insert(
|
||||
parsedNFTTxs.end(),
|
||||
parsedNFTTxsRef.begin(),
|
||||
parsedNFTTxsRef.end());
|
||||
EXPECT_EQ(parsedNFTTxs.size(), 1);
|
||||
EXPECT_TRUE(parsedNFT.has_value());
|
||||
EXPECT_EQ(parsedNFT->tokenID, nftID);
|
||||
std::vector<NFTsData> nftData;
|
||||
nftData.push_back(*parsedNFT);
|
||||
|
||||
backend->writeLedger(
|
||||
lgrInfoNext,
|
||||
std::move(ledgerInfoToBinaryString(lgrInfoNext)));
|
||||
@@ -335,6 +476,26 @@ TEST(BackendTest, Basic)
|
||||
std::move(std::string{txnBlob}),
|
||||
std::move(std::string{metaBlob}));
|
||||
backend->writeAccountTransactions(std::move(accountTxData));
|
||||
|
||||
// NFT writing not yet implemented for pg
|
||||
if (config == cassandraConfig)
|
||||
{
|
||||
backend->writeNFTs(std::move(nftData));
|
||||
backend->writeNFTTransactions(std::move(parsedNFTTxs));
|
||||
}
|
||||
else
|
||||
{
|
||||
EXPECT_THROW(
|
||||
{ backend->writeNFTs(std::move(nftData)); },
|
||||
std::runtime_error);
|
||||
EXPECT_THROW(
|
||||
{
|
||||
backend->writeNFTTransactions(
|
||||
std::move(parsedNFTTxs));
|
||||
},
|
||||
std::runtime_error);
|
||||
}
|
||||
|
||||
backend->writeLedgerObject(
|
||||
std::move(std::string{accountIndexBlob}),
|
||||
lgrInfoNext.seq,
|
||||
@@ -384,6 +545,34 @@ TEST(BackendTest, Basic)
|
||||
EXPECT_FALSE(cursor);
|
||||
}
|
||||
|
||||
// NFT fetching not yet implemented for pg
|
||||
if (config == cassandraConfig)
|
||||
{
|
||||
auto nft =
|
||||
backend->fetchNFT(nftID, lgrInfoNext.seq, yield);
|
||||
EXPECT_TRUE(nft.has_value());
|
||||
auto [nftTxns, cursor] = backend->fetchNFTTransactions(
|
||||
nftID, 100, true, {}, yield);
|
||||
EXPECT_EQ(nftTxns.size(), 1);
|
||||
EXPECT_EQ(nftTxns[0], nftTxns[0]);
|
||||
EXPECT_FALSE(cursor);
|
||||
}
|
||||
else
|
||||
{
|
||||
EXPECT_THROW(
|
||||
{
|
||||
backend->fetchNFT(
|
||||
nftID, lgrInfoNext.seq, yield);
|
||||
},
|
||||
std::runtime_error);
|
||||
EXPECT_THROW(
|
||||
{
|
||||
backend->fetchNFTTransactions(
|
||||
nftID, 100, true, {}, yield);
|
||||
},
|
||||
std::runtime_error);
|
||||
}
|
||||
|
||||
ripple::uint256 key256;
|
||||
EXPECT_TRUE(key256.parseHex(accountIndexHex));
|
||||
auto obj = backend->fetchLedgerObject(
|
||||
@@ -729,8 +918,7 @@ TEST(BackendTest, Basic)
|
||||
for (auto [account, data] : accountTx)
|
||||
{
|
||||
std::vector<Backend::TransactionAndMetadata> retData;
|
||||
std::optional<Backend::AccountTransactionsCursor>
|
||||
cursor;
|
||||
std::optional<Backend::TransactionsCursor> cursor;
|
||||
do
|
||||
{
|
||||
uint32_t limit = 10;
|
||||
|
||||
Reference in New Issue
Block a user