diff --git a/src/data/README.md b/src/data/README.md
index 27af08a1..0e9b4e01 100644
--- a/src/data/README.md
+++ b/src/data/README.md
@@ -1,42 +1,75 @@
# Backend
-## Background
-The backend of Clio is responsible for handling the proper reading and writing of past ledger data from and to a given database. As of right now, Cassandra and ScyllaDB are the only supported databases that are production-ready. Support for database types can be easily extended by creating new implementations which implements the virtual methods of `BackendInterface.h`. Then, use the Factory Object Design Pattern to simply add logic statements to `BackendFactory.h` that return the new database interface for a specific `type` in Clio's configuration file.
+The backend of Clio is responsible for handling the proper reading and writing of past ledger data from and to a given database. Currently, Cassandra and ScyllaDB are the only supported databases that are production-ready.
+
+To support additional database types, you can create new classes that implement the virtual methods in [BackendInterface.h](https://github.com/XRPLF/clio/blob/develop/src/data/BackendInterface.hpp). Then, leveraging the Factory Object Design Pattern, modify [BackendFactory.h](https://github.com/XRPLF/clio/blob/develop/src/data/BackendFactory.hpp) with logic that returns the new database interface if the relevant `type` is provided in Clio's configuration file.
## Data Model
-The data model used by Clio to read and write ledger data is different from what Rippled uses. Rippled uses a novel data structure named [*SHAMap*](https://github.com/ripple/rippled/blob/master/src/ripple/shamap/README.md), which is a combination of a Merkle Tree and a Radix Trie. In a SHAMap, ledger objects are stored in the root vertices of the tree. Thus, looking up a record located at the leaf node of the SHAMap executes a tree search, where the path from the root node to the leaf node is the key of the record. Rippled nodes can also generate a proof-tree by forming a subtree with all the path nodes and their neighbors, which can then be used to prove the existnce of the leaf node data to other Rippled nodes. In short, the main purpose of the SHAMap data structure is to facilitate the fast validation of data integrity between different decentralized Rippled nodes.
-Since Clio only extracts past validated ledger data from a group of trusted Rippled nodes, it can be safely assumed that these ledger data are correct without the need to validate with other nodes in the XRP peer-to-peer network. Because of this, Clio is able to use a flattened data model to store the past validated ledger data, which allows for direct record lookup with much faster constant time operations.
+The data model used by Clio to read and write ledger data is different from what `rippled` uses. `rippled` uses a novel data structure named [*SHAMap*](https://github.com/ripple/rippled/blob/master/src/ripple/shamap/README.md), which is a combination of a Merkle Tree and a Radix Trie. In a SHAMap, ledger objects are stored in the root vertices of the tree. Thus, looking up a record located at the leaf node of the SHAMap executes a tree search, where the path from the root node to the leaf node is the key of the record.
-There are three main types of data in each XRP ledger version, they are [Ledger Header](https://xrpl.org/ledger-header.html), [Transaction Set](https://xrpl.org/transaction-formats.html) and [State Data](https://xrpl.org/ledger-object-types.html). Due to the structural differences of the different types of databases, Clio may choose to represent these data using a different schema for each unique database type.
+`rippled` nodes can also generate a proof-tree by forming a subtree with all the path nodes and their neighbors, which can then be used to prove the existence of the leaf node data to other `rippled` nodes. In short, the main purpose of the SHAMap data structure is to facilitate the fast validation of data integrity between different decentralized `rippled` nodes.
-**Keywords**
-*Sequence*: A unique incrementing identification number used to label the different ledger versions.
-*Hash*: The SHA512-half (calculate SHA512 and take the first 256 bits) hash of various ledger data like the entire ledger or specific ledger objects.
-*Ledger Object*: The [binary-encoded](https://xrpl.org/serialization.html) STObject containing specific data (i.e. metadata, transaction data).
-*Metadata*: The data containing [detailed information](https://xrpl.org/transaction-metadata.html#transaction-metadata) of the outcome of a specific transaction, regardless of whether the transaction was successful.
-*Transaction data*: The data containing the [full details](https://xrpl.org/transaction-common-fields.html) of a specific transaction.
-*Object Index*: The pseudo-random unique identifier of a ledger object, created by hashing the data of the object.
+Since Clio only extracts past validated ledger data from a group of trusted `rippled` nodes, it can be safely assumed that the ledger data is correct without the need to validate with other nodes in the XRP peer-to-peer network. Because of this, Clio is able to use a flattened data model to store the past validated ledger data, which allows for direct record lookup with much faster constant time operations.
+
+There are three main types of data in each XRP Ledger version:
+
+- [Ledger Header](https://xrpl.org/ledger-header.html)
+
+- [Transaction Set](https://xrpl.org/transaction-formats.html)
+
+- [State Data](https://xrpl.org/ledger-object-types.html)
+
+Due to the structural differences of the different types of databases, Clio may choose to represent these data types using a different schema for each unique database type.
+
+### Keywords
+
+**Sequence**: A unique incrementing identification number used to label the different ledger versions.
+
+**Hash**: The SHA512-half (calculate SHA512 and take the first 256 bits) hash of various ledger data like the entire ledger or specific ledger objects.
+
+**Ledger Object**: The [binary-encoded](https://xrpl.org/serialization.html) STObject containing specific data (i.e. metadata, transaction data).
+
+**Metadata**: The data containing [detailed information](https://xrpl.org/transaction-metadata.html#transaction-metadata) of the outcome of a specific transaction, regardless of whether the transaction was successful.
+
+**Transaction data**: The data containing the [full details](https://xrpl.org/transaction-common-fields.html) of a specific transaction.
+
+**Object Index**: The pseudo-random unique identifier of a ledger object, created by hashing the data of the object.
## Cassandra Implementation
-Cassandra is a distributed wide-column NoSQL database designed to handle large data throughput with high availability and no single point of failure. By leveraging Cassandra, Clio will be able to quickly and reliably scale up when needed simply by adding more Cassandra nodes to the Cassandra cluster configuration.
-In Cassandra, Clio will be creating 9 tables to store the ledger data, they are `ledger_transactions`, `transactions`, `ledger_hashes`, `ledger_range`, `objects`, `ledgers`, `diff`, `account_tx`, and `successor`. Their schemas and how they work are detailed below.
+Cassandra is a distributed wide-column NoSQL database designed to handle large data throughput with high availability and no single point of failure. By leveraging Cassandra, Clio is able to quickly and reliably scale up when needed simply by adding more Cassandra nodes to the Cassandra cluster configuration.
-*Note, if you would like visually explore the data structure of the Cassandra database, you can first run Clio server with database `type` configured as `cassandra` to fill ledger data from Rippled nodes into Cassandra, then use a GUI database management tool like [Datastax's Opcenter](https://docs.datastax.com/en/install/6.0/install/opscInstallOpsc.html) to interactively view it.*
+In Cassandra, Clio creates 9 tables to store the ledger data:
+- `ledger_transactions`
+- `transactions`
+- `ledger_hashes`
+- `ledger_range`
+- `objects`
+- `ledgers`
+- `diff`
+- `account_tx`
+- `successor`
+
+Their schemas and how they work are detailed in the following sections.
+
+> **Note**: If you would like visually explore the data structure of the Cassandra database, run the Clio server with the database `type` configured as `cassandra` to fill ledger data from the `rippled` nodes into Cassandra. Then, use a GUI database management tool like [Datastax's Opcenter](https://docs.datastax.com/en/install/6.0/install/opscInstallOpsc.html) to interactively view it.
### ledger_transactions
+
```
CREATE TABLE clio.ledger_transactions (
ledger_sequence bigint, # The sequence number of the ledger version
hash blob, # Hash of all the transactions on this ledger version
PRIMARY KEY (ledger_sequence, hash)
) WITH CLUSTERING ORDER BY (hash ASC) ...
- ```
-This table stores the hashes of all transactions in a given ledger sequence ordered by the hash value in ascending order.
+```
+
+This table stores the hashes of all transactions in a given ledger sequence and is sorted by the hash value in ascending order.
### transactions
+
```
CREATE TABLE clio.transactions (
hash blob PRIMARY KEY, # The transaction hash
@@ -45,29 +78,36 @@ CREATE TABLE clio.transactions (
metadata blob, # Metadata of the transaction
transaction blob # Data of the transaction
) ...
- ```
+```
+
This table stores the full transaction and metadata of each ledger version with the transaction hash as the primary key.
-To look up all the transactions that were validated in a ledger version with sequence `n`, one can first get the all the transaction hashes in that ledger version by querying `SELECT * FROM ledger_transactions WHERE ledger_sequence = n;`. Then, iterate through the list of hashes and query `SELECT * FROM transactions WHERE hash = one_of_the_hash_from_the_list;` to get the detailed transaction data.
+To lookup all the transactions that were validated in a ledger version with sequence `n`, first get the all the transaction hashes in that ledger version by querying `SELECT * FROM ledger_transactions WHERE ledger_sequence = n;`. Then, iterate through the list of hashes and query `SELECT * FROM transactions WHERE hash = one_of_the_hash_from_the_list;` to get the detailed transaction data.
### ledger_hashes
+
```
CREATE TABLE clio.ledger_hashes (
hash blob PRIMARY KEY, # Hash of entire ledger version's data
sequence bigint # The sequence of the ledger version
) ...
- ```
+```
+
This table stores the hash of all ledger versions by their sequences.
+
### ledger_range
+
```
CREATE TABLE clio.ledger_range (
is_latest boolean PRIMARY KEY, # Whether this sequence is the stopping range
sequence bigint # The sequence number of the starting/stopping range
) ...
- ```
-This table marks the range of ledger versions that is stored on this specific Cassandra node. Because of its nature, there are only two records in this table with `false` and `true` values for `is_latest`, marking the starting and ending sequence of the ledger range.
+```
+
+This table marks the range of ledger versions that is stored on this specific Cassandra node. Because of its nature, there are only two records in this table with `false` and `true` values for `is_latest`, marking the starting and ending sequence of the ledger range.
### objects
+
```
CREATE TABLE clio.objects (
key blob, # Object index of the object
@@ -75,31 +115,37 @@ CREATE TABLE clio.objects (
object blob, # Data of the object
PRIMARY KEY (key, sequence)
) WITH CLUSTERING ORDER BY (sequence DESC) ...
- ```
-This table stores the specific data of all objects that ever existed on the XRP network, even if they are deleted (which is represented with a special `0x` value). The records are ordered by descending sequence, where the newest validated ledger objects are at the top.
+```
-This table is updated when all data for a given ledger sequence has been written to the various tables in the database. For each ledger, many associated records are written to different tables. This table is used as a synchronization mechanism, to prevent the application from reading data from a ledger for which all data has not yet been fully written.
+The `objects` table stores the specific data of all objects that ever existed on the XRP network, even if they are deleted (which is represented with a special `0x` value). The records are ordered by descending sequence, where the newest validated ledger objects are at the top.
+
+The table is updated when all data for a given ledger sequence has been written to the various tables in the database. For each ledger, many associated records are written to different tables. This table is used as a synchronization mechanism, to prevent the application from reading data from a ledger for which all data has not yet been fully written.
### ledgers
+
```
CREATE TABLE clio.ledgers (
sequence bigint PRIMARY KEY, # Sequence of the ledger version
header blob # Data of the header
) ...
- ```
+```
+
This table stores the ledger header data of specific ledger versions by their sequence.
### diff
+
```
CREATE TABLE clio.diff (
seq bigint, # Sequence of the ledger version
key blob, # Hash of changes in the ledger version
PRIMARY KEY (seq, key)
) WITH CLUSTERING ORDER BY (key ASC) ...
- ```
+```
+
This table stores the object index of all the changes in each ledger version.
### account_tx
+
```
CREATE TABLE clio.account_tx (
account blob,
@@ -107,10 +153,12 @@ CREATE TABLE clio.account_tx (
hash blob, # Hash of the transaction
PRIMARY KEY (account, seq_idx)
) WITH CLUSTERING ORDER BY (seq_idx DESC) ...
- ```
+```
+
This table stores the list of transactions affecting a given account. This includes transactions made by the account, as well as transactions received.
### successor
+
```
CREATE TABLE clio.successor (
key blob, # Object index
@@ -118,30 +166,35 @@ CREATE TABLE clio.successor (
next blob, # Index of the next object that existed in this sequence
PRIMARY KEY (key, seq)
) WITH CLUSTERING ORDER BY (seq ASC) ...
- ```
-This table is the important backbone of how histories of ledger objects are stored in Cassandra. The successor table stores the object index of all ledger objects that were validated on the XRP network along with the ledger sequence that the object was upated on. Due to the unique nature of the table with each key being ordered by the sequence, by tracing through the table with a specific sequence number, Clio can recreate a Linked List data structure that represents all the existing ledger object at that ledger sequence. The special value of `0x00...00` and `0xFF...FF` are used to label the head and tail of the Linked List in the successor table. The diagram below showcases how tracing through the same table but with different sequence parameter filtering can result in different Linked List data representing the corresponding past state of the ledger objects. A query like `SELECT * FROM successor WHERE key = ? AND seq <= n ORDER BY seq DESC LIMIT 1;` can effectively trace through the successor table and get the Linked List of a specific sequence `n`.
+```
+
+This table is the important backbone of how histories of ledger objects are stored in Cassandra. The `successor` table stores the object index of all ledger objects that were validated on the XRP network along with the ledger sequence that the object was updated on.
+
+As each key is ordered by the sequence, which is achieved by tracing through the table with a specific sequence number, Clio can recreate a Linked List data structure that represents all the existing ledger objects at that ledger sequence. The special values of `0x00...00` and `0xFF...FF` are used to label the *head* and *tail* of the Linked List in the successor table.
+
+The diagram below showcases how tracing through the same table, but with different sequence parameter filtering, can result in different Linked List data representing the corresponding past state of the ledger objects. A query like `SELECT * FROM successor WHERE key = ? AND seq <= n ORDER BY seq DESC LIMIT 1;` can effectively trace through the successor table and get the Linked List of a specific sequence `n`.
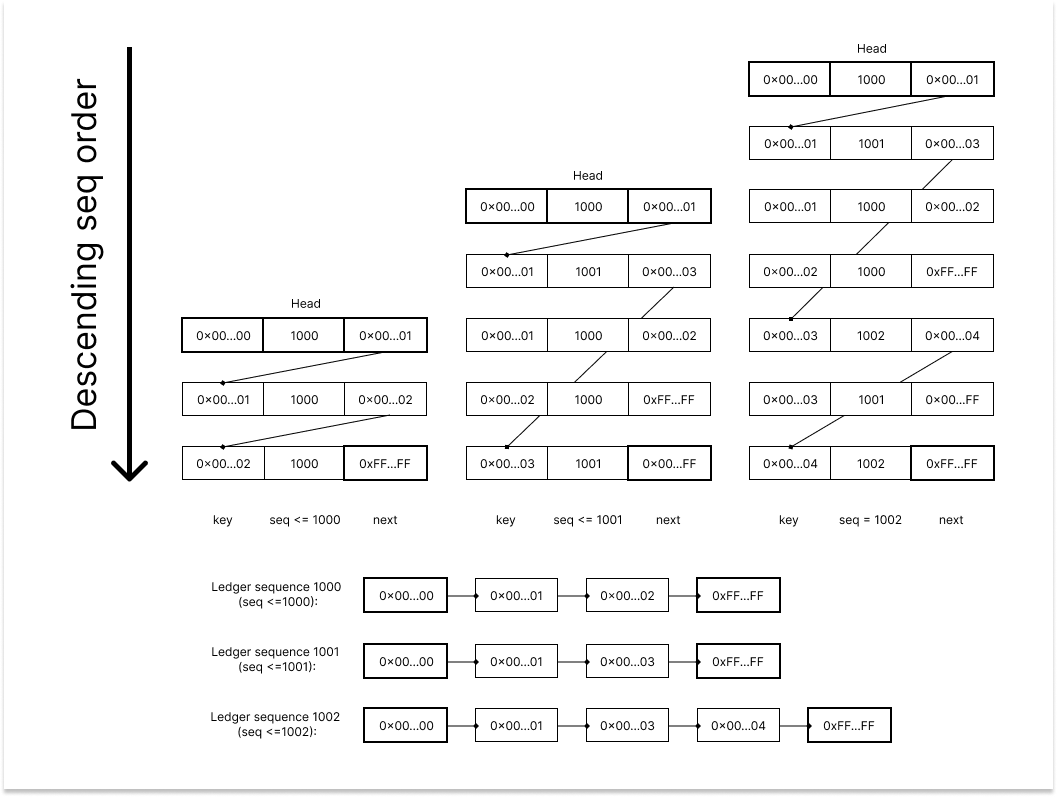
-*P.S.: The `diff` is `(DELETE 0x00...02, CREATE 0x00...03)` for `seq=1001` and `(CREATE 0x00...04)` for `seq=1002`, which is both accurately reflected with the Linked List trace*
-In each new ledger version with sequence `n`, a ledger object `v` can either be **created**, **modified**, or **deleted**. For all three of these operations, the procedure to update the successor table can be broken down in to two steps:
- 1. Trace through the Linked List of the previous sequence to to find the ledger object `e` with the greatest object index smaller or equal than the `v`'s index. Save `e`'s `next` value (the index of the next ledger object) as `w`.
+> **Note**: The `diff` is `(DELETE 0x00...02, CREATE 0x00...03)` for `seq=1001` and `(CREATE 0x00...04)` for `seq=1002`, which is both accurately reflected with the Linked List trace.
+
+In each new ledger version with sequence `n`, a ledger object `v` can either be **created**, **modified**, or **deleted**.
+
+For all three of these operations, the procedure to update the successor table can be broken down into two steps:
+
+ 1. Trace through the Linked List of the previous sequence to find the ledger object `e` with the greatest object index smaller or equal than the `v`'s index. Save `e`'s `next` value (the index of the next ledger object) as `w`.
+
2. If `v` is...
1. Being **created**, add two new records of `seq=n` with one being `e` pointing to `v`, and `v` pointing to `w` (Linked List insertion operation).
2. Being **modified**, do nothing.
3. Being **deleted**, add a record of `seq=n` with `e` pointing to `v`'s `next` value (Linked List deletion operation).
-### NFT data model
-In `rippled` NFTs are stored in NFTokenPage ledger objects. This object is
-implemented to save ledger space and has the property that it gives us O(1)
-lookup time for an NFT, assuming we know who owns the NFT at a particular
-ledger. However, if we do not know who owns the NFT at a specific ledger
-height we have no alternative in rippled other than scanning the entire
-ledger. Because of this tradeoff, clio implements a special NFT indexing data
-structure that allows clio users to query NFTs quickly, while keeping
-rippled's space-saving optimizations.
+## NFT data model
+
+In `rippled` NFTs are stored in `NFTokenPage` ledger objects. This object is implemented to save ledger space and has the property that it gives us O(1) lookup time for an NFT, assuming we know who owns the NFT at a particular ledger. However, if we do not know who owns the NFT at a specific ledger height we have no alternative but to scan the entire ledger in `rippled`. Because of this tradeoff, Clio implements a special NFT indexing data structure that allows Clio users to query NFTs quickly, while keeping rippled's space-saving optimizations.
+
+### nf_tokens
-#### nf_tokens
```
CREATE TABLE clio.nf_tokens (
token_id blob, # The NFT's ID
@@ -151,21 +204,21 @@ CREATE TABLE clio.nf_tokens (
PRIMARY KEY (token_id, sequence)
) WITH CLUSTERING ORDER BY (sequence DESC) ...
```
-This table indexes NFT IDs with their owner at a given ledger. So
+
+This table indexes NFT IDs with their owner at a given ledger.
+
+The example query below shows how you could search for the owner of token `N` at ledger `Y` and see whether the token was burned.
+
```
SELECT * FROM nf_tokens
WHERE token_id = N AND seq <= Y
ORDER BY seq DESC LIMIT 1;
```
-will give you the owner of token N at ledger Y and whether it was burned. If
-the token is burned, the owner field indicates the account that owned the
-token at the time it was burned; it does not indicate the person who burned
-the token, necessarily. If you need to determine who burned the token you can
-use the `nft_history` API, which will give you the NFTokenBurn transaction
-that burned this token, along with the account that submitted that
-transaction.
-#### issuer_nf_tokens_v2
+If the token is burned, the owner field indicates the account that owned the token at the time it was burned; it does not indicate the person who burned the token, necessarily. If you need to determine who burned the token you can use the `nft_history` API, which will give you the `NFTokenBurn` transaction that burned this token, along with the account that submitted that transaction.
+
+### issuer_nf_tokens_v2
+
```
CREATE TABLE clio.issuer_nf_tokens_v2 (
issuer blob, # The NFT issuer's account ID
@@ -174,13 +227,12 @@ CREATE TABLE clio.issuer_nf_tokens_v2 (
PRIMARY KEY (issuer, taxon, token_id)
) WITH CLUSTERING ORDER BY (taxon ASC, token_id ASC) ...
```
-This table indexes token IDs against their issuer and issuer/taxon
-combination. This is useful for determining all the NFTs a specific account
-issued, or all the NFTs a specific account issued with a specific taxon. It is
-not useful to know all the NFTs with a given taxon while excluding issuer, since the
-meaning of a taxon is left to an issuer.
-#### nf_token_uris
+This table indexes token IDs against their issuer and issuer/taxon
+combination. This is useful for determining all the NFTs a specific account issued, or all the NFTs a specific account issued with a specific taxon. It is not useful to know all the NFTs with a given taxon while excluding issuer, since the meaning of a taxon is left to an issuer.
+
+### nf_token_uris
+
```
CREATE TABLE clio.nf_token_uris (
token_id blob, # The NFT's ID
@@ -189,23 +241,17 @@ CREATE TABLE clio.nf_token_uris (
PRIMARY KEY (token_id, sequence)
) WITH CLUSTERING ORDER BY (sequence DESC) ...
```
-This table is used to store an NFT's URI. Without storing this here, we would
-need to traverse the NFT owner's entire set of NFTs to find the URI, again due
-to the way that NFTs are stored in rippled. Furthermore, instead of storing
-this in the `nf_tokens` table, we store it here to save space. A given NFT
-will have only one entry in this table (see caveat below), written to this
-table as soon as clio sees the NFTokenMint transaction, or when clio loads an
-NFTokenPage from the initial ledger it downloaded. However, the `nf_tokens`
-table is written to every time an NFT changes ownership, or if it is burned.
-Given this, why do we have to store the sequence? Unfortunately there is an
-extreme edge case where a given NFT ID can be burned, and then re-minted with
-a different URI. This is extremely unlikely, and might be fixed in a future
-version to rippled, but just in case we can handle that edge case by allowing
-a given NFT ID to have a new URI assigned in this case, without removing the
-prior URI.
+This table is used to store an NFT's URI. Without storing this here, we would need to traverse the NFT owner's entire set of NFTs to find the URI, again due to the way that NFTs are stored in `rippled`. Furthermore, instead of storing this in the `nf_tokens` table, we store it here to save space.
+
+A given NFT will have only one entry in this table (see caveat below), and will be written to this table as soon as Clio sees the `NFTokenMint` transaction, or when Clio loads an `NFTokenPage` from the initial ledger it downloaded. However, the `nf_tokens` table is written to every time an NFT changes ownership, or if it is burned.
+
+> **Why do we have to store the sequence?**
+>
+> Unfortunately there is an extreme edge case where a given NFT ID can be burned, and then re-minted with a different URI. This is extremely unlikely, and might be fixed in a future version of `rippled`. Currently, Clio handles this edge case by allowing the NFT ID to have a new URI assigned, without removing the prior URI.
+
+### nf_token_transactions
-#### nf_token_transactions
```
CREATE TABLE clio.nf_token_transactions (
token_id blob, # The NFT's ID
@@ -214,7 +260,5 @@ CREATE TABLE clio.nf_token_transactions (
PRIMARY KEY (token_id, seq_idx)
) WITH CLUSTERING ORDER BY (seq_idx DESC) ...
```
-This table is the NFT equivalent of `account_tx`. It's motivated by the exact
-same reasons and serves the analogous purpose here. It drives the
-`nft_history` API.
+The `nf_token_transactions` table serves as the NFT counterpart to `account_tx`, inspired by the same motivations and fulfilling a similar role within this context. It drives the `nft_history` API.
diff --git a/src/etl/README.md b/src/etl/README.md
index 0cb7f50b..e422cfe8 100644
--- a/src/etl/README.md
+++ b/src/etl/README.md
@@ -1,72 +1,40 @@
# ETL subsystem
-A single clio node has one or more ETL sources, specified in the config
-file. clio will subscribe to the `ledgers` stream of each of the ETL
-sources. This stream sends a message whenever a new ledger is validated. Upon
-receiving a message on the stream, clio will then fetch the data associated
-with the newly validated ledger from one of the ETL sources. The fetch is
-performed via a gRPC request (`GetLedger`). This request returns the ledger
-header, transactions+metadata blobs, and every ledger object
-added/modified/deleted as part of this ledger. ETL then writes all of this data
-to the databases, and moves on to the next ledger. ETL does not apply
-transactions, but rather extracts the already computed results of those
-transactions (all of the added/modified/deleted SHAMap leaf nodes of the state
-tree).
+A single Clio node has one or more ETL sources specified in the config file. Clio subscribes to the `ledgers` stream of each of the ETL sources. The stream sends a message whenever a new ledger is validated.
-If the database is entirely empty, ETL must download an entire ledger in full
-(as opposed to just the diff, as described above). This download is done via the
-`GetLedgerData` gRPC request. `GetLedgerData` allows clients to page through an
-entire ledger over several RPC calls. ETL will page through an entire ledger,
-and write each object to the database.
+Upon receiving a message on the stream, Clio fetches the data associated with the newly validated ledger from one of the ETL sources. The fetch is performed via a gRPC request called `GetLedger`. This request returns the ledger header, transactions and metadata blobs, and every ledger object added/modified/deleted as part of this ledger. The ETL subsystem then writes all of this data to the databases, and moves on to the next ledger.
-If the database is not empty, clio will first come up in a "soft"
-read-only mode. In read-only mode, the server does not perform ETL and simply
-publishes new ledgers as they are written to the database.
-If the database is not updated within a certain time period
-(currently hard coded at 20 seconds), clio will begin the ETL
-process and start writing to the database. The database will report an error when
-trying to write a record with a key that already exists. ETL uses this error to
-determine that another process is writing to the database, and subsequently
-falls back to a soft read-only mode. clio can also operate in strict
-read-only mode, in which case they will never write to the database.
+If the database is not empty, clio will first come up in a "soft" read-only mode. In read-only mode, the server does not perform ETL and simply publishes new ledgers as they are written to the database. If the database is not updated within a certain time period (currently hard coded at 20 seconds), clio will begin the ETL process and start writing to the database. The database will report an error when trying to write a record with a key that already exists. ETL uses this error to determine that another process is writing to the database, and subsequently falls back to a soft read-only mode. clio can also operate in strict read-only mode, in which case they will never write to the database.
## Ledger cache
+
To efficiently reduce database load and improve RPC performance, we maintain a ledger cache in memory. The cache stores all entities of the latest ledger as a map of index to object, and is updated whenever a new ledger is validated.
-The successor table stores each ledger's object indexes as a linked list
-,
-which is used by cache loader to load the all ledger objects belonging to the latest ledger to memory concurrently.
-The head of the linked list is data::firstKey(**0x0000000000000000000000000000000000000000000000000000000000000000**), and the tail is data::lastKey(**0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF**). The linked list is partitioned into
-multiple segments by cursors and each segment will be picked by a coroutine to load. There are total `cache.num_markers` coroutines to load the ledger objects concurrently. A coroutine will pick a segment from a queue and load it with the step of `cache.page_fetch_size` until the queue is empty.
+The `successor` table stores each ledger's object indexes as a Linked List.
+
-For example, if segment
-(**0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51-0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22**)
-is assigned to a coroutine, the coroutine will load the ledger objects from index
-**0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51** to
-**0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22**. The coroutine will request `cache.page_fetch_size`
-objects from database each time until reach the end of the segment. After the coroutine finishes loading this
-segment, it will fetch the next segment in queue and repeat.
-
-Because of the nature of the linked list, the cursors are crucial to balance the workload of each
-coroutine. We have 3 types of cursor generation can be used:
+The Linked List is used by the cache loader to load all ledger objects belonging to the latest ledger to memory concurrently. The head of the Linked List is data::firstKey(**0x0000000000000000000000000000000000000000000000000000000000000000**), and the tail is data::lastKey(**0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF**).
-- **cache.num_diffs**
-Cursors will be generated by the changed objects in the latest `cache.num_diffs` number of ledgers. The default value is 32. In mainnet, this type works well because the network is stablily busy and the number of changed objects in each ledger is relatively stable. We are able to get enough cursors after removing the deleted objects on mainnet. For other networks, like the devnet, the number of changed objects in each ledger is not stable. When the network is slient, one cotoutine may load a large number of objects while the other coroutines are idel.
-Here is the comparison of the number of cursors and loading time on devnet:
+The Linked List is partitioned into multiple segments by cursors and each segment will be picked by a coroutine to load. There are total `cache.num_markers` coroutines to load the ledger objects concurrently. A coroutine will pick a segment from a queue and load it with the step of `cache.page_fetch_size` until the queue is empty.
- | Cursors | Loading time /seconds |
- | --- | --- |
- | 11 | 2072 |
- | 33 | 983 |
- | 120 | 953 |
- | 200 | 843 |
- | 250 | 816 |
- | 500 | 792 |
+For example, if segment **0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51-0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22** is assigned to a coroutine, the coroutine will load the ledger objects from index **0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51** to
+**0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22**. The coroutine will continuously request `cache.page_fetch_size` objects from the database until it reaches the end of the segment. After the coroutine finishes loading this segment, it will fetch the next segment in the queue and repeat.
-- **cache.num_cursors_from_diff**
-Cursors will be generated by the changed objects in the recent ledgers. The generator will keep reading the previous ledger until we have `cache.num_cursors_from_diff` cursors. The type is the evolved version of the first type. It removes the network busyness factor and only considers the number of cursors. The cache loading can be well tuned by this configuration.
+Because of the nature of the Linked List, the cursors are crucial to balancing the workload of each coroutine. There are 3 types of cursor generation that can be used:
--- **cache.num_cursors_from_account**
-If the server does not have enough historical ledgers, another option is to generate the cursors by the account. The generator will keep reading accounts from account_tx table until we have `cache.num_cursors_from_account` cursors.
+- **cache.num_diffs**: Cursors will be generated by the changed objects in the latest `cache.num_diffs` number of ledgers. The default value is 32. In *mainnet*, this type works well because the network is fairly busy and the number of changed objects in each ledger is relatively stable. Thus, we are able to get enough cursors after removing the deleted objects on *mainnet*.
+For other networks, like the *devnet*, the number of changed objects in each ledger is not stable. When the network is silent, one coroutine may load a large number of objects while the other coroutines are idle. Below is a comparison of the number of cursors and loading time on *devnet*:
+ | Cursors | Loading time /seconds |
+ | ------- | --------------------- |
+ | 11 | 2072 |
+ | 33 | 983 |
+ | 120 | 953 |
+ | 200 | 843 |
+ | 250 | 816 |
+ | 500 | 792 |
+
+- **cache.num_cursors_from_diff**: Cursors will be generated by the changed objects in the recent ledgers. The generator will keep reading the previous ledger until we have `cache.num_cursors_from_diff` cursors. This type is the evolved version of `cache.num_diffs`. It removes the network busyness factor and only considers the number of cursors. The cache loading can be well tuned by this configuration.
+
+- **cache.num_cursors_from_account**: If the server does not have enough historical ledgers, another option is to generate the cursors by the account. The generator will keep reading accounts from the `account_tx` table until there are `cache.num_cursors_from_account` cursors.
diff --git a/src/main/Mainpage.hpp b/src/main/Mainpage.hpp
index ee84f51d..079d82b3 100644
--- a/src/main/Mainpage.hpp
+++ b/src/main/Mainpage.hpp
@@ -22,22 +22,21 @@
*
* @section intro Introduction
*
- * Clio is an XRP Ledger API server. Clio is optimized for RPC calls, over WebSocket or JSON-RPC.
+ * Clio is an XRP Ledger API server optimized for RPC calls over WebSocket or JSON-RPC.
*
- * Validated historical ledger and transaction data are stored in a more space-efficient format, using up to 4 times
- * less space than rippled.
+ * It stores validated historical ledger and transaction data in a more space efficient format, and uses up to 4 times
+ * less space than rippled.
*
- * Clio can be configured to store data in Apache Cassandra or ScyllaDB, allowing for scalable read throughput.
- * Multiple Clio nodes can share access to the same dataset, allowing for a highly available cluster of Clio nodes,
- * without the need for redundant data storage or computation.
- *
- * You can read more general information about Clio and its subsystems from the `Related Pages` section.
+ * Clio can be configured to store data in Apache Cassandra or
+ * ScyllaDB, enabling scalable read throughput. Multiple Clio nodes can share
+ * access to the same dataset, which allows for a highly available cluster of Clio nodes without the need for redundant
+ * data storage or computation.
*
* @section Develop
*
* As you prepare to develop code for Clio, please be sure you are aware of our current
* Contribution guidelines.
*
- * Read `rpc/README.md` carefully to know more about writing your own handlers for
+ * Read [rpc/README.md](../rpc/README.md) carefully to know more about writing your own handlers for
* Clio.
*/
diff --git a/src/rpc/README.md b/src/rpc/README.md
index 4e9777f5..80e40b91 100644
--- a/src/rpc/README.md
+++ b/src/rpc/README.md
@@ -1,22 +1,29 @@
# RPC subsystem
-## Background
The RPC subsystem is where the common framework for handling incoming JSON requests is implemented.
## Components
-See `common` subfolder.
+
+See the [common](https://github.com/XRPLF/clio/blob/develop/src/rpc/common) subfolder.
- **AnyHandler**: The type-erased wrapper that allows for storing different handlers in one map/vector.
- **RpcSpec/FieldSpec**: The RPC specification classes, used to specify how incoming JSON is to be validated before it's parsed and passed on to individual handler implementations.
-- **Validators/Modifiers**: A bunch of supported validators and modifiers that can be specified as requirements for each **`FieldSpec`** to make up the final **`RpcSpec`** of any given RPC handler.
+- **Validators/Modifiers**: A bunch of supported validators and modifiers that can be specified as requirements for each `FieldSpec` to make up the final `RpcSpec` of any given RPC handler.
## Implementing a handler
-See `unittests/rpc` for exmaples.
-Handlers need to fulfil the requirements specified by the **`SomeHandler`** concept (see `rpc/common/Concepts.h`):
-- Expose types:
- * `Input` - The POD struct which acts as input for the handler
- * `Output` - The POD struct which acts as output of a valid handler invocation
-- Have a `spec(uint32_t)` member function returning a const reference to an **`RpcSpec`** describing the JSON input for the specified API version.
+See [unittests/rpc](https://github.com/XRPLF/clio/tree/develop/unittests/rpc) for examples.
+
+Handlers need to fulfil the requirements specified by the `SomeHandler` concept (see `rpc/common/Concepts.hpp`):
+
+- Expose types:
+
+ - `Input` - The POD struct which acts as input for the handler
+
+ - `Output` - The POD struct which acts as output of a valid handler invocation
+
+- Have a `spec(uint32_t)` member function returning a const reference to an `RpcSpec` describing the JSON input for the specified API version.
+
- Have a `process(Input)` member function that operates on `Input` POD and returns `HandlerReturnType